Google does not match keywords to pages anymore. It matches entities and relationships to queries and intent and that shift changes everything about how you optimize.
Semantic SEO is structuring your content, your site architecture, and your markup so Google can identify what entities you cover, how those entities relate to each other, and why your site deserves to rank for the topic. Not just the keyword, but the actual topic.
If your SEO workflow still starts with a keyword list and ends with on-page placement and backlinks, I’m afraid you are optimizing for a version of Google that stopped existing years ago. Google’s systems now parse meaning at the query level, the document level, and the passage level. They resolve entities to Knowledge Graph entries and evaluate whether your site demonstrates real depth on a subject or just mentions it once.
This guide maps the full territory of semantic SEO for technical SEOs. It covers: the mechanism (how Google’s NLP models actually process your content), the strategy (entities, topical authority, semantic content structure, structured data) and the workflow – audit, entity map, implementation, validation.
Two things this guide assumes: you understand how crawling, indexing, and ranking work at a basic level, and you have access to Google Search Console. If both are true, start here.
60-Second Summary
Four things that drive semantic SEO.
- Entity optimization makes your content parseable – Google resolves your entities to Knowledge Graph entries.
- Topical authority proves you cover a subject fully, not just a single keyword within it.
- Semantic content structure organizes information around concepts, so Google understands how entities relate.
- Structured data in JSON-LD declares your entities explicitly in machine-readable code.
The implementation path: audit your semantic state -> build an entity map -> plan your topic clusters -> write entity-rich content -> add schema -> validate with Google’s NLP API.
AI Overviews now pull from content Google can structurally understand. If your entities are unclear, bad news is you are invisible to generative search.
Each section below covers one piece of this system and links to a full implementation guide.
Table of Contents
What Is Semantic SEO?
Semantic SEO is the practice of optimizing content around topics, entities, and the relationships between them.
- Topics – we optimize for a subject and its full scope, not a single search term.
- Entities. Writing about things Google can actually identify – people, organizations, concepts, places – and connect to its Knowledge Graph.
- Relationships. We make the connections between entities explicit, both in your content structure and in your markup.
For most of Google’s history, search worked by lexical matching. Ranking came down to which pages had the best combination of on-page signals and backlinks for the specific search term.
Honestly, that system did not disappear as Google still uses lexical signals heavily. Exact-match keywords in title tags, URLs, and H1s still influence ranking by a lot. What changed is that Google added semantic understanding on top of those lexical signals.
The query “who started the company that makes the iPhone” contains few keywords matching Apple’s Wikipedia page, but Google answers it anyway by resolving “the company that makes the iPhone” to the entity Apple Inc., then finding the founder attribute of that entity.
So lexical and semantic signals work together and neither replaced the other.
Entity-based understanding is the infrastructure of modern search, not a feature Google might roll back. Every major update since 2013 – Hummingbird, RankBrain, BERT, MUM – pushed Google further toward entity-based understanding.
Semantic SEO is just a different model of how search works, which requires a different model of how you plan, create, and structure content. Your content either fits this system or fights it.
How Does Semantic SEO Differ from Traditional SEO?
The workflows look different from step one.
Traditional SEO targets a query. Semantic SEO targets the concept behind the query – and every query that concept generates.
Traditional SEO follows a familiar path – keyword research -> pick target keywords and place them in title tag, headings, and body text ->build backlinks = rank for chosen keywords.
Semantic SEO starts somewhere else entirely:
First you identify the core entities in your topic. Then plan content that covers those entities with real depth. Now structure the relationships between them – through internal links, content organization, and schema markup – and you rank for the topic and every variation of how someone might ask about it.
A traditional approach to this page would target the keyword “semantic SEO” and optimize for that exact string. A semantic approach targets the concept of semantic SEO – which means also covering entities, the Knowledge Graph, topical authority, structured data, NLP, and how they all connect. Keywords still matter, but the actual concept is what ranks.
And technical fundamentals still matter. Crawl efficiency, site speed, clean URL structures, quality backlinks – none of that goes away. Meanwhile semantic SEO builds on top of those fundamentals. It adds a layer of meaning that Google’s current systems actively look for and reward.
For a side-by-side breakdown with practical examples, see our full comparison: how semantic SEO differs from traditional optimization.
Why Does Semantic SEO Matter Right Now?
Nowadays Google’s ranking systems parse meaning at three levels: the query, the document, and individual passages within the document. Although what really changed is where that understanding goes.
AI Overviews now appear in roughly 16% of all queries, according to a Semrush analysis of over 10 million keywords tracked through November 2025. That number peaked near 25% mid-year before Google pulled back.
Here is what that means for your traffic. A Seer Interactive study tracking 3,119 informational queries across 42 organizations found that organic CTR dropped from 1.76% to 0.64% for queries where AI Overviews appeared – a 61% decline over fifteen months. And paid CTR fell even harder, from 19.7% to 6.34%.
The content that holds its visibility has one thing in common: Google can structurally understand it. Google’s systems parse it into entities and relationships, then synthesize those into the AI-generated answer. If your content is not parseable at the entity level, it does not get cited but rather summarized over.
I would consider this a discoverability problem. According to SparkToro/Datos research from 2024, roughly 58.5% of Google queries in the US end without a click – a figure other analyses put even higher. When someone reads an AI Overview that synthesizes your expertise without linking to you, you influenced a decision with zero attribution. The sites that avoid this are the ones Google can identify as authoritative sources on specific entities.
How Do AI Overviews Change the Game for Entity-Rich Content?
AI Overviews work by synthesizing answers from content Google has already parsed into entities and relationships. Google’s own documentation describes a “query fan-out” technique – the system issues multiple related searches across sub-topics and data sources to build a response, then identifies supporting web pages to link as sources. The underlying engine is Gemini — Google’s multimodal LLM, and the same model that decides what gets cited.
The AI is not finding the best page for a keyword. It’s finding the best entity coverage across multiple sources, then assembling an answer. Your page gets cited when Google’s models can clearly identify which entities you cover and how authoritatively you cover them.
Does structured data guarantee inclusion? No. Google’s Search Central documentation is explicit: “You don’t need to create new machine readable files, AI text files, or markup to appear in these features.” Standard SEO fundamentals apply. But pages with clear entity definitions get cited more often in AI Overviews. Industry analyses from BrightEdge and SE Ranking suggest correlation, though no single study has isolated structured data as a direct causal factor for AI Overview citation.
The reason is straightforward. Schema does not unlock a special AI Overview ranking signal. But it removes ambiguity. When your Article schema declares about properties pointing to specific Wikidata entities, Google does not have to guess what your page covers because it already knows. Content with unambiguous entity declarations is easier to select as a source when the AI system fans out across sub-topics.
This is where semantic SEO and structured data intersect. Your semantic content tells Google how entities relate to each other, while your schema confirms which entities are on the page. Together, they make your content machine-readable at the level AI Overviews require.
For a deeper look at how structured data feeds into generative search features, see our [guide on how structured data connects to AI Overviews] (coming soon).
How Does Google Actually Understand Meaning?
The pipeline, simplified: Google crawls your page, its NLP models parse the text and extract entities, it resolves those entities against the Knowledge Graph, maps the relationships between them, and indexes your content by concept – not just by keyword.
Google crawls your page, its NLP models parse the text and extract entities, it resolves those entities against the Knowledge Graph, maps the relationships between them, and indexes your content by concept — not just by keyword.”
Every step in that pipeline is a point where your content either registers semantically or gets treated as just another page of text. The sections below break down each one.

What Are Entities – and Why Does Google Build a Graph Around Them?
An entity is a thing that’s singular, unique, well-defined, and distinguishable. A person. A place. A concept. An organization. A product. The word “entity” in this context comes from information science, not SEO jargon.
Google’s Knowledge Graph is a database that stores these entities along with their attributes and relationships. Google describes it as “our database of billions of facts about people, places, and things.” In May 2020, Google reported it contained 500 billion facts across 5 billion entities. According to third-party tracking by Kalicube and SEL, the Knowledge Graph had grown to roughly 50 billion entities by mid-2025, though Google conducted a significant cleanup in June 2025 that removed over 3 billion entities in a single week – prioritizing clarity and precision over sheer volume. Google has not formally disclosed these figures.
Keywords are ambiguous. Entities are not.
The keyword “Apple” appears in content about fruit, technology, record labels, and the city in Texas. The entity Apple Inc. has a defined type (Organization), attributes (CEO, headquarters, founding year), and relationships (parent of Apple Music, competitor of Microsoft, listed on NASDAQ). When Google resolves the word “Apple” on your page to the entity Apple Inc., it does not just know what word you used. It knows exactly which entity your page covers.
Your content connects to the Knowledge Graph through three channels: entity mentions in your text that Google’s NLP models can extract, Schema.org markup that explicitly declares entities, and links to authoritative knowledge bases like Wikidata and Wikipedia that resolve entity identity directly.
Entity SEO – optimizing your content to be understood as part of this graph – is the foundation of everything else in semantic SEO.
How Do Google’s NLP Models Parse Your Content?
Google does not read your page the way you do. It runs your text through a stack of NLP models, each designed to extract a different layer.
Hummingbird (2013) was the foundational update that shifted Google toward semantic query interpretation. Before Hummingbird, Google parsed queries word by word. Hummingbird allowed Google to interpret the intent of a full query as a unit, matching it to concepts rather than individual terms. It’s the reason entity-based understanding exists at all in modern search.
RankBrain launched in 2015 as Google’s first machine learning system applied to search. It handles query interpretation – specifically ambiguous and novel queries that Google has never seen before. RankBrain maps unfamiliar queries to concepts Google already understands. If someone types a question Google has never encountered, RankBrain connects it to known entities and topics based on patterns learned from billions of previous searches.
BERT rolled out in 2019 and changed how Google reads language at the word level. BERT stands for Bidirectional Encoder Representations from Transformers. The key word is bidirectional – it processes every word in context with the words before and after it, simultaneously. Before BERT, Google struggled with prepositions, negation, and nuance. The query “2019 brazil traveler to usa need a visa” used to return results about Americans traveling to Brazil because Google ignored the word “to.” BERT fixed that. At launch in 2019, Google reported BERT affected one in ten English searches in the US. Google’s Danny Sullivan has since stated that BERT and its successors now affect the majority of queries.
BERT and models like it don’t just classify words – they produce embeddings: dense vector representations that place words and passages in a high-dimensional semantic space. Two passages about the same concept will have similar vector representations even if they share no keywords. This is how Google computes semantic similarity between a query and a document: not by counting matching words, but by measuring the distance between their vector representations. The field of vector search and dense retrieval is foundational to how modern search engines match content to queries. Our [Vector Databases for SEO guide] (coming soon) covers the technical side in depth.
MUM (Multitask Unified Model) was announced in 2021. It’s multimodal and multilingual – capable of understanding text, images, and video, and transferring knowledge across 75 languages. MUM represents Google’s push toward understanding everything about a topic, not just the query. Google has confirmed specific MUM applications – including COVID vaccine name matching and “things to know” refinements – but has not confirmed it processes every page for ranking the way BERT does. Where BERT improved word-level comprehension, MUM enables Google to connect information across content types and languages to assess topical completeness.
Gemini is the current generative layer sitting on top of this stack. Where BERT and MUM handle document understanding and topical assessment, Gemini is the multimodal model that powers AI Overviews – synthesizing structured knowledge from multiple sources into a composed answer. For SEOs, the takeaway is simple: the entity clarity and topical depth that help classic ranking also feed the Gemini-powered generative layer. The same content signals that get you ranked get you cited.
What does this stack mean for your content in practice? Google reads your page at the passage level. Each passage is evaluated for entity salience – how prominently and clearly you discuss each entity – relationship clarity, and topical relevance. A technique called named-entity recognition identifies the entities in your text, categorizes them by type, and scores their importance to the page. Keyword repetition does not increase entity salience. Writing clearly about an entity in proper context does.
We break down each model’s impact on ranking – and what it means for how you write – in our Google’s NLP guide.
How Does Google Resolve Entity Ambiguity?
Let’s say we write a page that mentions “Mercury.” Google needs to determine which Mercury you mean: the planet, the chemical element, the Roman god, the car brand, or the record label founded by Irving Green in 1945.
Google uses several signals to resolve ambiguity. Surrounding context is the strongest – if your page mentions “Mercury” alongside “orbit,” “atmosphere,” and “NASA,” the planet wins. Co-occurring entities reinforce the decision. Mentioning “Venus” and “Mars” in the same content cluster points to astronomy, not mythology. Structured data types provide explicit disambiguation – an Article schema with an about property pointing to the Wikidata entry for Mercury (planet) removes all ambiguity in a single declaration. Links to knowledge bases work the same way – a hyperlink to the Wikipedia article for Mercury the planet tells Google exactly which entity you mean.
However, if Google cannot disambiguate the entities on your page, it cannot index your page by the right concepts. Your page about Mercury the planet might get partially associated with Mercury the element, diluting your semantic relevance for both. You lose topical authority on the entity you actually cover.
Good news is the fix is straightforward. Name entities precisely. Provide context through co-occurring entities. Use schema about and mentions properties with Wikidata URIs. Link to the correct knowledge base entry. Every one of these signals reduces ambiguity and strengthens the connection between your content and the right node in Google’s entity graph.
Our full guide to entity disambiguation covers the signals, the common mistakes, and the implementation fixes in detail.
What Are the Four Pillars of a Semantic SEO Strategy?
Semantic SEO is not one technique. It’s four interlocking practices that reinforce each other. Remove one and the other three weaken.
- Entity optimization makes your entities identifiable and unambiguous. You define what things your content covers, connect them to knowledge bases, and ensure Google resolves them correctly. This is the foundation – without it, nothing else registers semantically.
- Topical authority proves comprehensive coverage. You cannot rank for a topic by publishing one page. You rank by demonstrating that your site covers the subject and its sub-topics with real depth.
- Semantic content structure organizes your writing around meaning, not keywords. Your content architecture, your internal links, and the way you sequence information all signal how entities relate to each other.
- Structured data gives Google explicit entity declarations in machine-readable code. Your content implies entities. Your schema confirms them.
These are not sequential steps you complete one at a time. They are concurrent. You build all four together, because each one makes the others stronger.
How Do You Build Topical Authority?
Most sites don’t have topical authority. They published eight blog posts about related keywords over two years and assume Google sees them as an authority on the subject. It doesn’t.
Topical authority means your site covers a subject comprehensively – not just one keyword within it, but the full map of entities, sub-topics, and questions that define the topic. Google infers this from three signals: the breadth of entity coverage across your pages, the internal linking density between related content, and the consistency of publishing within a topic over time.
Think about what this means practically. If you write one article about semantic SEO, you will rank for a few long-tail keywords around semantic SEO (if you are lucky). If you write about semantic SEO and entities and topical authority and the Knowledge Graph and structured data and entity disambiguation – and you link all of those pages to each other in a coherent structure – Google starts treating your site as a genuine resource on the topic. You rank for queries you never explicitly targeted, because Google understands that your site covers the concept, not just the keyword.
This is where most SEO strategies break down. Teams pick keywords from a tool, assign them to blog posts, publish them on a loose editorial calendar, and never connect them structurally. While the content exists, the architecture does not. Google sees isolated pages, not a topic.
Our full guide to building topical authority covers the measurement framework and the step-by-step build process.
How Should You Structure Your Topic Architecture?
There are two dominant models for organizing topical content: topic clusters and content silos.
A topic cluster uses hub-and-spoke linking. One pillar page maps the full territory of a topic. Cluster articles cover each sub-topic in depth. Every cluster article links back to the pillar, and the pillar links out to every cluster article. The linking is bidirectional and relatively flat.
A content silo uses strict hierarchical separation. Content is grouped into categories that rarely cross-link. Each silo operates as an independent vertical, with internal links flowing within the silo but not between silos.
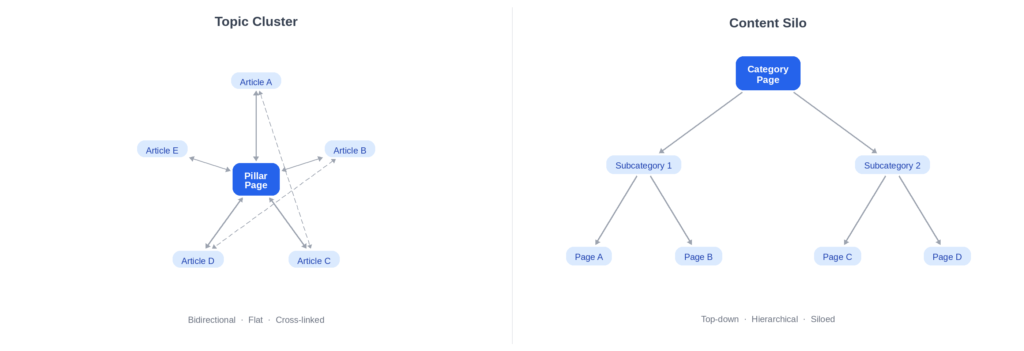
The page you are reading right now is a topic cluster in action. This pillar page covers the full scope of semantic SEO. Fourteen cluster articles each go deep on a sub-topic – entities, NLP, topical authority, disambiguation, structured data, and more. Every section of this page links to the relevant cluster guide, and each cluster guide links back here. That structure is the topical authority signal.
When should you use which model? Clusters work best when your sub-topics are tightly related and readers benefit from cross-navigation – exactly the case for a subject like semantic SEO, where understanding entities helps you understand disambiguation, which helps you understand structured data. Silos work better when your content categories are genuinely distinct and cross-linking would confuse rather than clarify. We compare both architectures with implementation examples in our guide on topic clusters and content silos.
One point applies to either model: internal links are the signal layer. Every link between related pages tells Google that a relationship exists between those topics. The anchor text of those links tells Google what the relationship is about. Without deliberate internal linking, your content is a collection of unconnected pages – no matter how good each individual page is.
How Do Semantic Keywords and Search Intent Work Together?
Semantic keywords are not synonyms. This is the most common misunderstanding, and it leads people down the wrong path immediately.
A synonym for “semantic SEO” might be “meaning-based optimization.” That’s just a different way of saying the same thing. A semantic keyword for “semantic SEO” is “Knowledge Graph” or “entity salience” or “topical authority” – a conceptually related term that signals depth of coverage on the topic.
The distinction matters because of how Google evaluates your content. When Google’s NLP models parse this page, they don’t just check whether the phrase “semantic SEO” appears in the headings. They extract entities and assess whether the page covers the concepts that define the topic. A page about semantic SEO that never mentions entities, structured data, or NLP is a page that does not actually understand its own subject.
This is about conceptual completeness, not keyword density. You include semantic keywords because covering the related entities and concepts proves to Google that your content has real depth – not because stuffing extra terms into your paragraphs earns a higher score.
But depth without direction is useless – and that’s what search intent solves.
Search intent is the reason behind the query – what the person actually needs when they type those words. An informational query needs explanation and context. A commercial query needs comparison and evaluation. A navigational query needs a direct path to a specific resource. Semantic keyword coverage only works when the content matches the intent. You can write the most entity-rich, topically comprehensive page on the internet, and it will not rank if it delivers an informational essay when the searcher needs a product comparison.
How Do You Find and Map Semantic Keywords?
The process starts with your target entity (not your target keyword).
Identify the core entity your page covers. Then map outward – what related entities define this topic, what attributes each has, and what terms people use to reference them.
For this page, the core entity is semantic SEO. The related entities include: Knowledge Graph, entity types, BERT, topical authority, structured data, Schema.org, named-entity recognition, search intent. Each of those entities has its own attributes and relationships. The map of all these connections is what tells you which semantic keywords to cover – and, just as importantly, how to organize them.
Each major entity cluster becomes a section of your content. That’s not a coincidence. It’s the structural principle behind this entire pillar page. Every H2 maps to a major entity in the semantic SEO topic. Every H3 maps to a related entity or attribute within that cluster. The content structure mirrors the entity map.
Several sources help you build the map. Google’s “People Also Ask” boxes show you the questions real users connect to your topic. Related searches at the bottom of the SERP reveal conceptual neighbors. Google’s Natural Language API lets you run your own content – and your competitors’ – through entity extraction to see which entities Google identifies and how salient it considers them. Dedicated semantic SEO tools like Surfer, MarketMuse, and InLinks automate parts of this process by analyzing top-ranking content for entity and topic coverage gaps. For a full breakdown of these tools, see our semantic SEO tools guide.
Our semantic keywords guide walks through the full research and mapping process: how to find and use semantic keywords.
How Does Structured Data Work as the Entity Layer?
Your content implies entities and your structured data confirms them.
That distinction is the entire reason structured data matters for semantic SEO. When you write clearly about the Knowledge Graph, Google’s NLP models extract that entity from your text. When you add Schema.org markup declaring that your article is about the Knowledge Graph – with a direct link to its Wikidata entry – Google doesn’t have to guess.
Structured data in JSON-LD format is how you make entity declarations explicit and machine-readable. It does not replace good semantic content. A page with perfect schema and thin content will not rank. But a page with entity-rich writing and accurate schema gives Google two reinforcing signals – one inferred from your text, one declared in your code. That combination is stronger than either alone.
Your semantic content is the essay. Your structured data is the bibliography. Both tell the story of what entities your page covers, but the bibliography removes ambiguity about which specific entities you mean.
The schema types that matter most for semantic SEO: Article, Organization, Person, FAQPage, and HowTo. Each has a dedicated implementation guide in the structured data pillar.
Google’s Structured Data General Guidelines apply to all of these. The core rule: your markup must represent content that’ss actually visible on the page. Schema is a declaration of what exists, not an invention of what does not.
How Do You Connect Your Schema to the Knowledge Graph?
Three properties bridge the gap between your markup and Google’s entity graph: sameAs, about, and mentions.
sameAslinks your entity to its canonical entries across the web. For an Organization or Person, this means pointing to your Wikipedia page, your Wikidata entry, and your verified social profiles. These links tell Google: “This entity on my site is the same as this known entity in your graph.”aboutdeclares the primary topic of your content. It answers the question: what entity is this page about? Point it to the Wikidata URI for the concept, and Google knows exactly which node in the Knowledge Graph your page maps to.mentionsdeclares secondary entities that appear in your content but are not the primary subject. A page about semantic SEO might mention the Knowledge Graph, BERT, and Schema.org as supporting entities.
This JSON-LD declares an Article about semantic SEO that mentions three related entities, each linked to their Wikidata entries using @id nodes:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Semantic SEO: The Complete Guide",
"description": "A strategic and technical guide to semantic SEO for practitioners.",
"author": {
"@type": "Organization",
"@id": "https://squin.org/#organization",
"name": "squin.org",
"url": "https://squin.org"
},
"publisher": {
"@id": "https://squin.org/#organization"
},
"about": {
"@type": "Thing",
"@id": "https://www.wikidata.org/wiki/Q180711",
"name": "Search engine optimization",
"sameAs": "https://en.wikipedia.org/wiki/Search_engine_optimization"
},
"mentions": [
{
"@type": "Thing",
"@id": "https://www.wikidata.org/wiki/Q648625",
"name": "Knowledge Graph",
"sameAs": "https://en.wikipedia.org/wiki/Knowledge_Graph_(Google)"
},
{
"@type": "Thing",
"@id": "https://www.wikidata.org/wiki/Q66086013",
"name": "BERT",
"sameAs": "https://en.wikipedia.org/wiki/BERT_(language_model)"
},
{
"@type": "Thing",
"@id": "https://www.wikidata.org/wiki/Q3475322",
"name": "Schema.org",
"sameAs": "https://en.wikipedia.org/wiki/Schema.org"
}
]
}
Every entity uses an @id pointing to a Wikidata URI – stable, unique identifiers Google can resolve directly to Knowledge Graph entries. No ambiguity. No inference required.
However, this is just a minimal example. Our JSON-LD tutorial covers the full pattern – including nested entities, @id-based cross-referencing across multiple schema blocks on a single page, and validation.
These three properties – sameAs, about, mentions – are how you move from “Google found keywords on my page” to “Google knows which entities my page covers and how they connect.”
For the complete implementation framework – every schema type, every property, every validation step – see the schema markup guide.
How Does E-E-A-T Connect to Entity SEO?
E-E-A-T – Experience, Expertise, Authoritativeness, Trustworthiness – is not a ranking factor. Google has said this repeatedly. It’s a framework that Google’s quality raters use to evaluate search results, as described in the Search Quality Rater Guidelines. But the signals Google’s algorithms use to assess these qualities are increasingly entity-based.
Consider what Google needs to evaluate trust. It needs to know who created the content and whether that person or organization has credible expertise on the topic. That’s an entity question.
Start with the author. Does Google know who wrote this page? Can it connect that name to a Knowledge Graph entity – a person with published credentials, verified profiles, and a track record of writing about this subject? If your author is a named entity with sameAs links to LinkedIn, a professional profile, and relevant publications, Google has a basis for evaluating expertise. If your author is “Admin” with no schema, no bio, and no external presence, Google has nothing to work with.
The same applies to the publishing organization. Does Google recognize your site’s publisher as an entity? Does your Organization schema include sameAs links to your Wikipedia entry, your Wikidata entry, your verified social profiles? These connections don’t guarantee trust. They give Google the data to evaluate it.
E-E-A-T assessment requires entity identification. You can write the most authoritative content on the internet, but if the entities behind it are invisible to Google’s systems, that authority goes unrecognized.
This is where E-E-A-T stops being a content quality concept and becomes a technical SEO problem. The fix is entity clarity: Person schema for authors, Organization schema for publishers, sameAs links to authoritative profiles, and consistent entity references across your site and the broader web.
We cover the full E-E-A-T entity framework – including Person and Organization schema patterns – in our guide on how E-E-A-T connects to entity SEO.
How Do You Implement Semantic SEO – Step by Step?
The four pillars described above work together, but implementation is sequential. Each step produces an output that the next step requires. Skip a step and the rest of the workflow breaks down.
Step 1: Audit Your Current Semantic State
A semantic SEO audit tells you where you stand right now across five dimensions.
- Entity coverage. Which entities does your site currently cover? Which ones does it miss? Run your top pages through entity extraction and compare the results against what your topic requires.
- Topical depth gaps. Where does your content stop short? If you cover semantic SEO but never mention entity disambiguation or the Knowledge Graph, those are gaps that weaken your topical authority.
- Schema validation. Is your existing structured data valid, complete, and connected? Or is it a collection of isolated schema blocks with no @id references and no links to knowledge bases?
- Internal link structure. Do your pages connect in a way that signals topical relationships? Or are they orphaned posts with no linking architecture?
- Knowledge Graph presence. Does your organization or brand exist as an entity in Google’s Knowledge Graph? Search your brand name and look for a Knowledge Panel. If there is none, Google does not yet recognize you as a distinct entity.
The audit tells you where you are. Everything else tells you where to go. Our semantic SEO audit guide walks you through the full checklist.
Step 2: Build Your Entity Map
An entity map is the strategic document that drives everything else. It’s a structured inventory of every entity your site should cover: what each entity is, what type it is (person, concept, organization, product), how it relates to other entities in your topic, and which pages on your site currently cover it.
This is not a keyword list. It’s a map of the concepts your site needs to own. Each entity becomes a content target. Each relationship between entities becomes an internal link. Each entity type determines which schema you use.
For a site covering semantic SEO, the entity map might include: semantic SEO (core entity), Knowledge Graph, entities, topical authority, BERT, Schema.org, E-E-A-T, entity disambiguation – plus the relationships between them. That map is what this pillar page is built on.
Our entity mapping guide gives you the process and template for building an entity map. For enterprise-scale sites with hundreds of entity types across multiple topic verticals, see our guide to advanced entity mapping techniques.
Step 3: Write Entity-Rich Content
Knowing your entities is not enough. How you write about them determines whether Google’s NLP models extract them with high salience.
The difference is specificity and context. Compare these two passages covering the same entity:
- “Topical authority is important for SEO. Sites that cover topics well tend to rank better.”
- “Topical authority is Google’s assessment of how comprehensively your site covers a subject. Google infers it from three signals: breadth of entity coverage across your pages, internal linking density between related content, and publishing consistency within a topic over time. A site that covers semantic SEO, entity disambiguation, the Knowledge Graph, and structured data – and links all of those pages together – signals deeper topical coverage than one that published a single keyword-targeted post.”
The second passage defines the entity precisely, names its attributes, and places it in relationship to other entities Google can identify. That context is what drives high entity salience scores. Writing more words doesn’t help. Writing with entity precision does.
Step 4: Build Entity-Aware Links
Traditional link building targets domain authority. You get a backlink from a high-DR site and hope the authority flows to your pages. Entity-aware link building targets something different: entity co-occurrence and knowledge base connections.
The goal is to get your entity mentioned and linked to in contexts that reinforce its type, attributes, and relationships. For example, a mention of your organization on a Wikipedia article about your industry does more for entity recognition than a guest post backlink from an unrelated site. A citation in a research paper that links to your author’s profile strengthens the author entity. A partnership page that describes your organization alongside its competitors and category reinforces entity type and attributes.
This is a fundamentally different way to think about outreach. You are not chasing authority metrics. You are building the web of references that Google uses to confirm entity identity.
Our full guide covers the strategy, outreach templates, and measurement framework: entity-based link building.
Step 5: Validate with the NLP API
You have written entity-rich content. You have added schema. You think Google will extract the right entities with the right salience. But how do you know?
The Google Cloud Natural Language API lets you test exactly that. Send your content to the API and it returns a list of entities it identifies, their types, their salience scores (how prominent each entity is on the page), and links to their Knowledge Graph entries where they exist.
A minimal cURL call to run any text through the API. This uses API key authentication for simplicity; for production use, Google recommends service account credentials or gcloud auth tokens.
curl -X POST \
"https://language.googleapis.com/v1/documents:analyzeEntities?key=YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{"document":{"type":"PLAIN_TEXT","content":"Your page content here"},"encodingType":"UTF8"}'
Running a sentence from earlier in this article through the API: “Google uses RankBrain to map unfamiliar queries to concepts it already understands.”
The API returns the raw structural data Google uses to parse your text. Here is the actual output for that sentence, truncated to the top two entities:
{
"entities":[
{
"name": "RankBrain",
"type": "OTHER",
"metadata": {
"mid": "/g/11bx2nrdx9",
"wikipedia_url": "https://en.wikipedia.org/wiki/RankBrain"
},
"salience": 0.584,
"mentions":[
{
"text": {
"content": "RankBrain",
"beginOffset": 12
},
"type": "PROPER"
}
]
},
{
"name": "Google",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.231,
"mentions":[
{
"text": {
"content": "Google",
"beginOffset": 0
},
"type": "PROPER"
}
]
}
],
"language": "en"
}
Three things matter in this output.
- The mid (Machine Identifier). Because RankBrain and Google both have a mid and a wikipedia_url, Google has successfully resolved them from ambiguous text into known nodes in its Knowledge Graph. An entity without a mid is one Google recognizes but cannot connect to its graph. That entity exists in your content but not in Google’s structured understanding of the world.
- The type. Google correctly categorizes Google as an ORGANIZATION and RankBrain as OTHER (algorithm/concept). If Google mistyped an entity – classifying a person as an organization, or a product as a concept – that’s a disambiguation signal you need to fix in your content. Co-occurring entities and schema about properties are how you correct it.
- Most importantly, the salience score. Salience runs from 0 to 1, and the scores across all entities on a page sum to approximately 1.0. That means salience is relative – entities compete for share. RankBrain (0.584) holds a much higher salience than Google (0.231) in this example, even though Google is the grammatical subject of the sentence. If this page were about the Google corporation, that salience distribution would tell you the passage needs rewriting to shift topical focus.
This example uses a single sentence to show the output structure. In practice, you send your full page text. The API returns every entity it extracts, ranked by salience across the entire document. On a 5,000-word page with dozens of entities competing for salience share, your primary topic might score 0.12 rather than 0.58 – that’s normal. What matters is whether it holds the highest score relative to every other entity on the page.
Your primary topic entity should always hold the highest salience on the page.
If a secondary entity – a tool name, a competing concept, a cited source – scores higher, your content is giving it more prominence than your core topic. Revise to rebalance.
Use this as a validation loop: write or revise, run the API, check the salience ranking, adjust. It’s the closest thing to a test suite for semantic SEO.
Our full guide shows you how to use Google’s NLP API to validate entity salience – including how to interpret salience scores, how to benchmark against competitors, and when to revise.
Common Mistakes in Semantic SEO Implementation
These are the errors that consistently appear in audits, regardless of site size or industry:
- Treating entities like keywords. Repeating an entity name throughout a page does not increase its salience. Write about the entity – its attributes, relationships, and context – rather than just naming it repeatedly.
- Schema without content depth. Adding Article schema with Wikidata about properties on a thin page does not create a semantic signal. Schema amplifies semantic content; it does not replace it. Google’s NLP models confirm what your schema declares. If the text does not support the declaration, the markup loses its effect.
- Orphaned entities. An entity that appears on one page with no internal links pointing to related entities is a dead end for Google’s entity graph. Every core entity in your topic map needs at least two or three connected pages that reinforce it.
- Ignoring disambiguation. Writing about “Mercury” without co-occurring entity context forces Google to guess which entity you mean. The more ambiguous your entities, the less precisely Google can index your page. Always provide contextual signals – co-occurring entities, schema about properties with Wikidata URIs, and links to knowledge base entries.
- Validating schema without checking salience. The Rich Results Test confirms that your JSON-LD is syntactically valid. It does not tell you whether your target entity is the most salient entity on the page. Use the NLP API for that. Both validation steps are necessary.
- Linking across unrelated topic verticals. Internal links that cross topic boundaries dilute the topical signal. If your semantic SEO content links heavily to pages about social media marketing with no topical connection, it weakens the cluster signal.
How Do You Measure Semantic SEO Results?
The wrong way to measure semantic SEO: check whether you rank #1 for your target keyword.
The right way: track whether your visibility is expanding across the entire topic.
- Query cluster impressions (Google Search Console). Filter your Performance report by queries related to your topic and track total impressions over time. Gaining impressions for queries you never explicitly targeted – variations, long-tail questions, related sub-topics – means topical authority is compounding. Google is associating your site with the broader concept, not just the specific keyword.
- Rich result appearances. Track which pages trigger rich results, which schema types are generating them, and whether coverage is growing. If your Article, FAQPage, and HowTo markup starts producing rich results where it did not before, Google is reading and validating your entity declarations.
- Knowledge Panel triggers. Search your organization name and your primary author’s name. If a Knowledge Panel appears, Google has established entity identity. If it doesn’t, you have more work to do on the
sameAsconnections and external entity references described in the E-E-A-T section. - Entity coverage via the Knowledge Graph API. Use the Knowledge Graph Search API to check whether Google associates your target entities with any results from your domain. Run branded searches and look at the “People also search for” suggestions – those reveal which entities Google connects to your brand.
The clearest sign that semantic SEO is working: you rank for more queries within your topic without publishing new pages. Your existing content starts capturing queries it was not originally written for, because Google understands the topical depth you have already built.
Frequently Asked Questions
What is semantic search in SEO?
Semantic search is Google’s ability to understand the meaning behind a query – not just match keywords. It uses entities, context, and intent to return results that answer what you actually meant, even if your query doesn’t contain the exact words on the page.
What is the difference between SEO and semantic SEO?
Traditional SEO optimizes pages for specific keywords. You research a keyword, place it in your title and headings, build backlinks, and rank for that term. Semantic SEO optimizes for topics, entities, and relationships. The core difference: traditional SEO asks “what keyword do I target?” Semantic SEO asks “what concept do I need to be the best resource for?”
What is a semantic keyword in SEO?
A semantic keyword is a term conceptually related to your target topic. Not a synonym – a concept that signals topical depth. For a page about “semantic SEO,” semantic keywords include entities, Knowledge Graph, topical authority, and structured data. Covering them proves to Google that your content understands the subject.
How does Google use entities for ranking?
Google identifies entities in your content using NLP models, resolves them to Knowledge Graph entries, and uses entity relationships to assess topical relevance. Pages with clear, unambiguous entity signals rank for broader topic queries – not just the exact keyword they target.
Do you need structured data for semantic SEO?
Structured data is not required. Google’s NLP models can extract entities from well-written content without any markup. But schema dramatically accelerates Google’s ability to identify your entities. Think of semantic content as the essay and schema as the bibliography – both tell the story, but the bibliography removes ambiguity.
What is the 80/20 of semantic SEO?
If you do nothing else: identify the ten core entities your site should own, create comprehensive content for each one, add Article schema with about properties pointing to Wikidata URIs, and interlink everything. That covers roughly 80% of the impact. The remaining 20% comes from entity disambiguation, advanced schema patterns, NLP validation, and entity-aware link building – each covered in the guides below.
Where to Go From Here
Every section above introduced a sub-topic and linked to its dedicated guide. Here is the full directory, organized by where you are in the process. Articles marked [Coming Phase X] are planned and in production – the topic map is complete even where the articles are not yet live.
Understand the Foundations
- What Is Entity SEO?
- Semantic SEO vs Traditional SEO
- Semantic Keywords: How to Find and Use Them
- How Google’s NLP Processes Content
Build Your Strategy
- Topical Authority: How to Build It
- Topic Clusters vs Content Silos
- Entity Disambiguation in SEO
- E-E-A-T and Entity SEO
Implement and Measure
- How to Build an Entity Map
- How to Build an Entity Map (Advanced)
- Entity-Based Link Building
- Google NLP API for SEO
- How to Do a Semantic SEO Audit
Tools
See the complete SEO Tools for Semantic SEO guide for the full toolkit.
- Surfer SEO vs Clearscope
- InLinks Review
- Screaming Frog for Structured Data Audits
- MarketMuse vs Frase [Coming – Phase 4]
- Vector Databases for SEO [Coming – Phase 4]
- Knowledge Graph Search API Guide [Coming – Phase 4]
Several additional guides are in development: semantic content structure, semantic internal linking strategy, Knowledge Graph mechanics for SEO, and semantic SEO for AI Overviews (citation optimization, entity-rich passage structure, and AI Mode visibility).