Entity SEO is how you make your content about things Google can identify – not just words it can match. This is the implementation layer of semantic SEO: you optimize for entities (people, places, concepts, organizations), and Google connects those entities to its Knowledge Graph for ranking and features.
This guide covers how Google extracts entities from your content, how to signal them through both writing and schema markup, and how to validate that Google sees what you intend. Working code included. No theory without implementation.
What Is an Entity in SEO?
An entity is a thing that is singular, unique, well-defined, and distinguishable. That’s Google’s working definition, drawn from how search engine entities function in the Knowledge Graph.
“Apple” as a text string is ambiguous. It could mean fruit, a technology company, or a record label. “Apple Inc.” as an entity is not ambiguous. It has a unique identifier (MID: /m/0k8z), a defined type (Organization), attributes (CEO, headquarters, founding date), and relationships to other entities (subsidiary of none, parent of Apple Music, competitor of Microsoft).
That identifier is the key to entity identifier SEO. Google assigns every recognized entity a machine ID – a MID – that persists across languages, spellings, and contexts. The Japanese Wikipedia article about Apple Inc. and the English one both resolve to the same MID. Google doesn’t rely on matching the word “Apple.” It matches the entity.
Your content contains entities whether you optimize for them or not. Entity SEO is ensuring Google extracts the right entities and connects them to the right Knowledge Graph entries. When that connection fails – when Google can’t determine which “Mercury” you mean or whether “Jordan” refers to a country or a basketball player – your content loses semantic precision.
Why Entity SEO Matters
Entity associations are structural. Keyword rankings shift with every algorithm update. Entity relationships sit in Google’s knowledge infrastructure and persist because they describe what things are, not just what words appear on a page.
Knowledge Panels require entity recognition. If Google doesn’t identify your brand as a distinct entity in the Knowledge Graph, you’re not eligible for a panel. That’s the threshold.
AI Overviews depend on entities for grounding. Google’s generative features appear to use retrieval-augmented generation (RAG) techniques, pulling facts from structured sources including the Knowledge Graph. This reduces hallucination by anchoring answers to verified entity data. Content with clear entity signals becomes a citable source. Content without them gets summarized over – or ignored entirely.
How Do Entities Differ from Keywords?
Keywords are text strings. Entities are concepts with unique identifiers. That’s the core distinction – often summarized as “things not strings.”
The keyword “Apple” appears in content about fruit, technology companies, and record labels. Google sees the same five characters in all three contexts. The entity Apple Inc. (Wikidata Q312) is unambiguous. It has one identifier, one definition, one set of attributes and relationships that persist regardless of how you spell it, translate it, or reference it.
Google’s search evolution moved from matching query strings against page strings to understanding what queries mean and matching that meaning to page entities. You type “who founded the iPhone company.” Google doesn’t look for pages containing that exact phrase. It resolves “iPhone company” to the entity Apple Inc., finds the “founder” relationship in the Knowledge Graph, and returns Steve Jobs – without needing any page to contain your query verbatim.
This is where semantic triples SEO becomes relevant. Entities don’t exist in isolation. They exist in relationships, structured as subject-predicate-object:
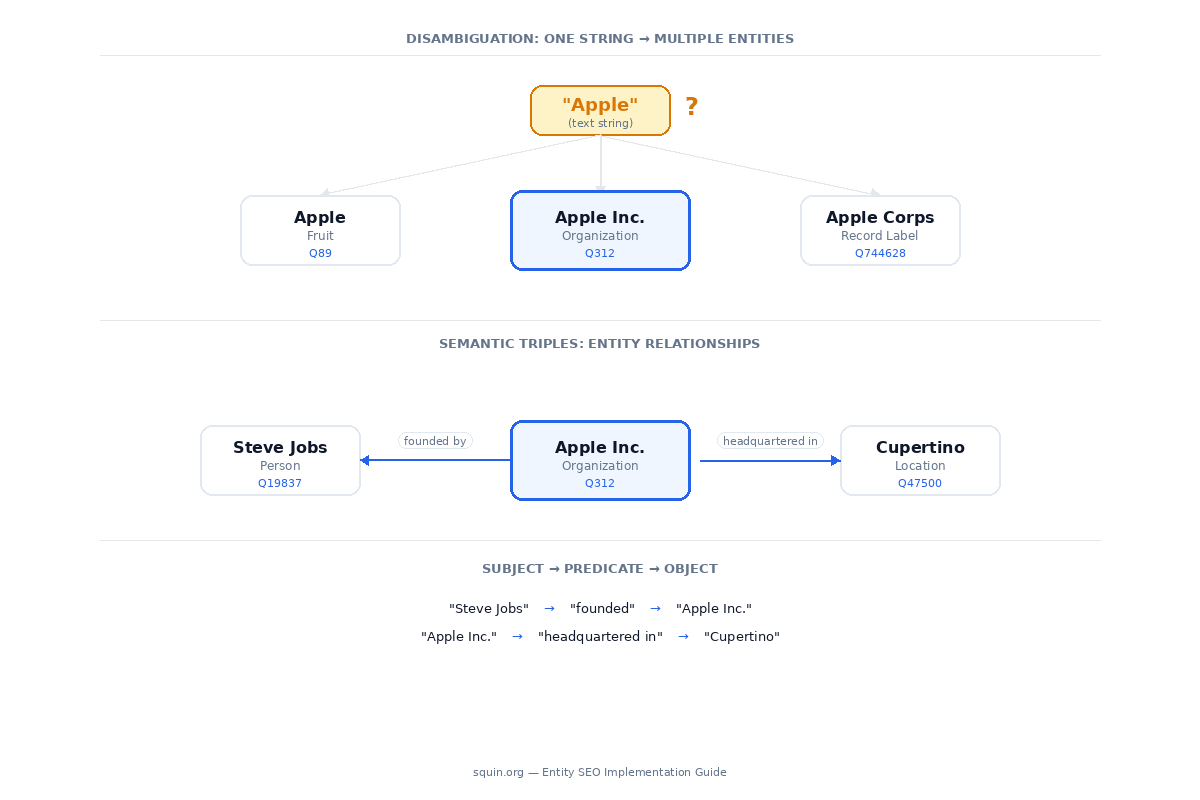
- “Steve Jobs” → “founded” → “Apple Inc.”
- “Apple Inc.” → “headquartered in” → “Cupertino”
- “Tim Cook” → “CEO of” → “Apple Inc.”
Each triple connects two entities through a defined relationship. The Knowledge Graph is billions of these triples. When your content establishes entity relationships SEO – when you write “Steve Jobs co-founded Apple Inc. in 1976 alongside Steve Wozniak” – you’re giving Google a parseable triple, not just keywords in proximity.
Content that establishes relationships signals topical understanding. Content that repeats keywords signals nothing except that you know which words to repeat.
How Does Google Identify Entities on Your Page?
Google runs your content through NLP models that extract entities, score their importance, and match them to Knowledge Graph entries. Understanding this pipeline tells you what to optimize.
Named-Entity Recognition
Google’s systems use named-entity recognition (NER) to identify and classify entities in your text. NER scans your content, identifies text spans that represent entities, and assigns each one a type: PERSON, ORGANIZATION, LOCATION, EVENT, CONSUMER_GOOD, WORK_OF_ART, and others.
Extraction happens at the passage level. Google doesn’t just evaluate your page as one block of text. It processes sections independently, which means an entity prominent in your introduction might not carry that prominence into a later section that shifts focus.
Not every noun becomes an entity. Google looks for proper nouns, defined concepts, and things that have – or could have – Knowledge Graph entries. “The company” is not an entity. “Apple Inc.” is. Generic terms get skipped. Specific, identifiable things get extracted.
Entity Salience
Salience measures how central an entity is to your content. Google’s NLP API returns salience as a score from 0 to 1, with scores distributed relative to each other. The most central entity scores highest.
Entities compete for salience share. A page mentioning 50 entities dilutes each one. A page focused on three entities gives each one meaningful weight.
Your primary topic should hold the highest salience score on the page. If you’re writing about Apple Inc.’s financial performance and Google returns Tim Cook with higher salience than Apple Inc., your content emphasis is wrong.
Salience is not keyword density. Repeating “Apple Inc.” twenty times doesn’t increase its salience. Writing substantively about Apple Inc. – its revenue, its products, its market position – does. Context and depth drive salience. Repetition doesn’t.
Knowledge Graph Matching and Disambiguation
Once extracted, Google attempts to match each entity to a Knowledge Graph entry. A successful match returns a MID (machine identifier), a Wikipedia URL, and a defined entity type. That’s confirmation: Google connected your text to a known thing.
An unsuccessful match means Google recognized something as an entity but couldn’t connect it to existing Knowledge Graph data. The entity exists on your page but floats without structured context.
Ambiguous entities – “Mercury,” “Jordan,” “Paris” – require disambiguation signals. Co-occurring entities help: mention “orbit” and “NASA” alongside “Mercury” and the planet wins. Schema declarations with Wikidata URIs make it explicit. For the full disambiguation workflow, see our guide on entity disambiguation.
How Do You Signal Entities to Google?
Two layers: content and schema. Content signals help Google’s NLP extract the right entities. Schema signals make those declarations explicit and machine-readable. You need both.
Content-Level Signals
Name entities precisely. Write “Apple Inc.” when you mean the company, not “Apple.” Write “Paris, France” when you mean the city, not “Paris.” Precision removes ambiguity before Google’s NLP has to guess.
Provide co-occurring entities. Mentioning “Tim Cook,” “iPhone,” and “Cupertino” alongside “Apple” pushes Google toward the technology company interpretation. Co-occurring entities act as disambiguation signals – they establish context that makes your primary entity unambiguous. Find co-occurring entities by checking the target entity’s Wikidata page for related properties, reviewing Wikipedia’s “See also” sections, or running competitor content through entity extraction tools.
Establish entity relationships SEO in your prose. The sentence “Steve Jobs co-founded Apple Inc. in 1976” gives Google a semantic triple to extract: Steve Jobs → founded → Apple Inc. That’s a parseable relationship, not just keywords in proximity. Write sentences that connect entities through defined relationships.
Write with entity focus, not keyword focus. Cover the entity’s attributes (founding date, headquarters, leadership), relationships (competitors, subsidiaries, founders), and context (industry, market position). This builds salience. Repeating the entity name builds nothing.
For site-level entity planning across multiple pages, see how to build an entity map.
Schema-Level Signals
Structured data makes your entity declarations explicit. Google’s NLP infers entities from your content. Schema markup confirms them.
Two schema.org properties matter most for entity SEO:
aboutdeclares the primary entity your page covers. This answers: what is this page about?mentionsdeclares secondary entities that appear but aren’t the main subject.
Both properties accept Thing types with an @id pointing to a Wikidata URI. Wikidata URIs are stable, machine-readable identifiers that connect directly to Knowledge Graph entries. When you declare "@id": "http://www.wikidata.org/entity/Q312", you’re telling Google exactly which entity you mean – Apple Inc., not the fruit, not the record label.
For Person and Organization entities, add sameAs arrays pointing to Wikipedia, Wikidata, and verified social profiles. These connections reinforce entity identity across the web.
For full JSON-LD syntax and nesting patterns, see our JSON-LD tutorial. For brand-specific implementation, see our guide on Organization schema.
Working Example
This JSON-LD block declares an Article’s primary entity (about) and secondary entities (mentions), each linked to Wikidata:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Understanding Entity SEO",
"datePublished": "2026-03-09T08:00:00+00:00",
"dateModified": "2026-03-09T08:00:00+00:00",
"image": "https://squin.org/wp-content/uploads/entity-seo-guide.png",
"author": {
"@type": "Person",
"@id": "https://squin.org/#jaan-koppel",
"name": "Jaan Koppel",
"url": "https://squin.org/about/",
"sameAs": [
"https://www.linkedin.com/in/jaankoppel",
"https://x.com/jaankoppel"
]
},
"publisher": {
"@type": "Organization",
"@id": "https://squin.org/#organization",
"name": "Squin.org",
"url": "https://squin.org",
"logo": {
"@type": "ImageObject",
"url": "https://squin.org/wp-content/uploads/squin-logo.png"
}
},
"about": {
"@type": "Thing",
"@id": "http://www.wikidata.org/entity/Q180711",
"name": "Search engine optimization",
"sameAs": "https://en.wikipedia.org/wiki/Search_engine_optimization"
},
"mentions": [
{
"@type": "Thing",
"@id": "http://www.wikidata.org/entity/Q648625",
"name": "Knowledge Graph",
"sameAs": "https://en.wikipedia.org/wiki/Google_Knowledge_Graph"
},
{
"@type": "Thing",
"@id": "http://www.wikidata.org/entity/Q30642",
"name": "Wikidata",
"sameAs": "https://en.wikipedia.org/wiki/Wikidata"
}
]
}
The @id values use Wikidata’s entity namespace (/entity/Q...), not the wiki page path. This is the machine-readable format for linked data. The author and publisher objects include their own @id references for cross-linking with other schema blocks on your site.
Validate your markup against Google’s structured data documentation before deploying. The Rich Results Test confirms syntax. It doesn’t confirm that Google will extract your intended entities from the content itself.
How Do You Validate Entity Extraction?
Schema validation confirms your markup is syntactically correct. Entity validation confirms Google extracts what you intend. Different problems. Different tools.
The Google Cloud Natural Language API runs Google’s own NLP models on your content and returns exactly what those models extract: entities, types, salience scores, and Knowledge Graph matches. This is the closest you get to seeing what Google sees.
To use the API, enable the Cloud Natural Language API in your Google Cloud Console and generate an API key. The free tier allows 5,000 requests per month.
A minimal API call:
curl -X POST \
"https://language.googleapis.com/v1/documents:analyzeEntities?key=YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{"document":{"type":"PLAIN_TEXT","content":"Tim Cook serves as CEO of Apple Inc., the technology company headquartered in Cupertino, California."},"encodingType":"UTF8"}'
The response returns an array of entities:
{
"entities": [
{
"name": "Apple Inc.",
"type": "ORGANIZATION",
"salience": 0.52,
"metadata": {
"mid": "/m/0k8z",
"wikipedia_url": "https://en.wikipedia.org/wiki/Apple_Inc."
}
},
{
"name": "Tim Cook",
"type": "PERSON",
"salience": 0.28,
"metadata": {
"mid": "/m/0ckqz",
"wikipedia_url": "https://en.wikipedia.org/wiki/Tim_Cook"
}
},
{
"name": "Cupertino",
"type": "LOCATION",
"salience": 0.12,
"metadata": {
"mid": "/m/01_d4",
"wikipedia_url": "https://en.wikipedia.org/wiki/Cupertino,_California"
}
}
]
}
Three things to check in every response:
Does your primary entity have the highest salience? In this example, Apple Inc. scores 0.52 while Tim Cook scores 0.28. The content is correctly weighted toward the company. If Tim Cook scored higher, you’d need to revise the content to increase Apple Inc.’s prominence.
Does Google return a mid and wikipedia_url? If yes, Knowledge Graph match succeeded. Google connected your text to a known entity. If these fields are missing, Google recognized something as an entity but couldn’t link it to existing knowledge. Add disambiguation signals: co-occurring entities in content, about property with Wikidata URI in schema.
Is the entity type correct? If Google classifies your organization as a PERSON or your product as an EVENT, something in your content is confusing the model. Check how you’ve described the entity. Add clarifying context.
Run this check before publishing. Run it again after major content revisions. Five minutes of validation prevents months of ranking for the wrong entities.
For the complete workflow – including batch processing, output interpretation, and competitor benchmarking – see the Google NLP API guide.
Common Entity SEO Mistakes
Six errors that undermine entity optimization. Each one is avoidable.
- Treating entity SEO as “just add schema.” Schema markup amplifies content signals. It doesn’t replace them. If your prose doesn’t clearly establish which entities the page covers, adding JSON-LD with
aboutandmentionsproperties won’t fix the problem. Google’s NLP extracts entities from your content first. Schema confirms what should already be there. - Repeating entity names instead of covering them. Salience comes from context, depth, and relationship establishment – not frequency. Writing “Apple Inc.” fifteen times doesn’t increase Apple Inc.’s salience score. Writing about Apple Inc.’s revenue, product lines, leadership, and market position does.
- No disambiguation for ambiguous terms. You mention “Mercury” without co-occurring entities or schema declarations. Google guesses. Maybe it picks the planet. Maybe the element. Maybe the Roman god. You don’t know, and neither does Google until you provide signals that resolve the ambiguity.
- Ignoring the
aboutproperty. Most sites add Organization schema for the company and Person schema for authors. Almost none declare what the page itself is about. Theaboutproperty exists for exactly this purpose. - Skipping validation. You assume Google extracts your target entity with the highest salience. You never verify. The NLP API takes five minutes to confirm what Google actually sees. That’s five minutes against months of optimizing for entities Google never identified correctly.
- Conflating “becoming an entity” with “covering entities well.” Getting your brand recognized in the Knowledge Graph is one goal. It matters for Knowledge Panels and brand search. But most pages on your site aren’t about your brand. They’re about topics – and those topics have entities too.
Frequently Asked Questions
What is an entity in SEO?
An entity is a thing that is singular, unique, well-defined, and distinguishable. People, places, organizations, concepts, products – anything Google can identify and track in its Knowledge Graph qualifies. Unlike keywords, entities have unique identifiers (MIDs) that persist across languages, spellings, and contexts. The entity Apple Inc. is the same whether you search in English, Japanese, or German.
What is the difference between keywords and entities?
Keywords are text strings. Entities are the concepts those strings refer to. The keyword “Apple” appears in content about fruit, technology, and music. The entity Apple Inc. (Wikidata Q312) is unambiguous – one identifier, one definition, one set of relationships. Google’s systems resolve keywords to entities to understand what content means, not just what words it contains.
How do you do entity SEO?
Two layers. At the content level: name entities precisely, provide co-occurring entities for disambiguation, and write sentences that establish relationships between entities. At the schema level: use the about and mentions properties with Wikidata URIs to declare which entities your page covers. Validate both layers with Google’s Cloud Natural Language API to confirm extraction matches intent.
What is an example of entity-based SEO?
A page about Apple’s financial performance uses entity SEO when it names “Apple Inc.” explicitly, mentions related entities like “Tim Cook” and “NASDAQ,” includes Article schema with an about property pointing to Apple Inc.’s Wikidata entry (Q312), and verifies via the NLP API that Apple Inc. holds the highest salience score on the page.
Where This Fits
Entity SEO is one implementation layer within the broader semantic SEO framework. For handling ambiguous entities that could resolve to multiple Knowledge Graph entries, see entity disambiguation. For planning entity coverage across your entire site, start with how to build an entity map.