
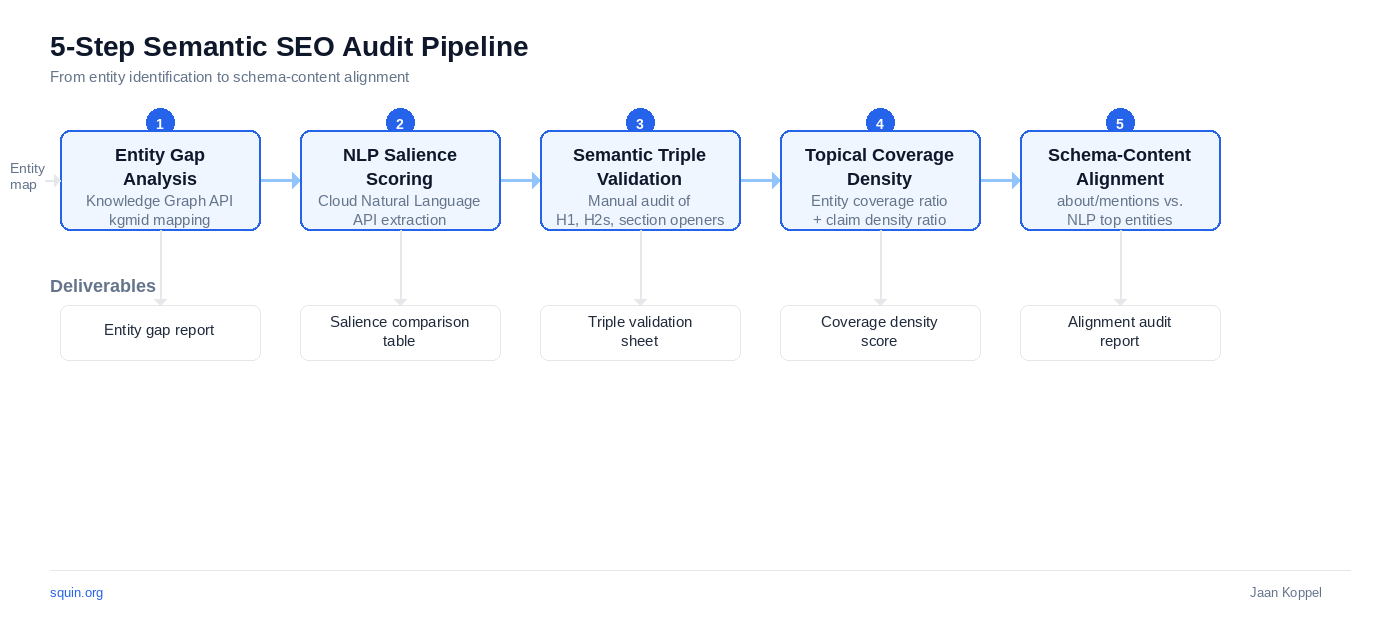
A semantic SEO audit answers five questions about your content. Do your pages target the right entities? Does Google’s NLP agree with your intent? Do your claims form machine-readable triples? Does your site cover the topic cluster deeply enough? Does your schema match what the NLP actually extracts?
The semantic SEO guide covers why entity signals, NLP salience, and topical authority matter. This guide is the measurement layer – how you audit all three on a live site.
Each step produces a specific deliverable: an entity gap report, a salience score comparison, a triple validation sheet, a coverage density metric, and a schema-content alignment check. Five artifacts. No guesswork about what “optimized” means when you’re done.
How Does a Semantic Audit Differ from a Traditional SEO Audit?
A traditional SEO audit checks infrastructure. Crawlability, indexation, page speed, canonical tags, keyword density. It answers one question: can Google find and render this page?
A semantic SEO audit checks understanding. Entity coverage, salience alignment, triple clarity, topical depth, schema-content consistency. Different question entirely: does Google understand what this page is actually about?
The distinction matters in practice. You can pass every traditional audit check – clean crawl, fast load, proper canonicals, keyword in the title – and still rank poorly. The reason: Google’s NLP extracts a different primary entity than the one you’re targeting.
A real pattern. You optimize a page for “knowledge graph optimization.” Title tag includes the phrase, H2s reference it, internal links use it as anchor text. Traditional audit says the page is clean. But run that URL through the Cloud Natural Language API, and the highest-salience entity comes back as “search engine optimization.” Google doesn’t see your page as being about Knowledge Graph work. It sees a generic SEO page. Structurally sound but semantically misaligned.
That gap – between what you intend and what NLP extracts – is what a semantic audit measures. The five steps that follow give you a repeatable process to find and close it.
| Step | What you’re measuring | Core question | Deliverable |
|---|---|---|---|
| 1 | Entity gap analysis | Are you targeting the right entities? | Entity gap report with kgmid mappings |
| 2 | NLP salience scoring | Does Google’s NLP agree with your intent? | Salience comparison table (yours vs. competitors) |
| 3 | Semantic triple validation | Do your claims form machine-readable triples? | Triple validation sheet per page |
| 4 | Topical coverage density | Does your site cover the cluster deeply enough? | Coverage density score per topic cluster |
| 5 | Schema-content alignment | Does your schema match what NLP actually extracts? | Schema-content alignment audit |
How Do You Run an Entity Gap Analysis?
Entity gap analysis maps the distance between the entities you’re targeting and the entities Google actually extracts from your content. Three steps: identify your target entities and verify they exist in the Knowledge Graph, score how salient those entities are in your content via NLP, then benchmark your scores against the pages that already rank.
Map Target Entities with the Knowledge Graph Search API
Start with the entity map for your topic cluster – a list of target entities with their names and Wikipedia or Wikidata URIs. That’s your audit baseline.
For each entity on that map, you need to answer one question: does Google’s Knowledge Graph have a disambiguated record for it? The Knowledge Graph Search API gives you that answer through Knowledge Graph ID (kgmid) mapping.
import requests
def lookup_kgmid(entity_name, api_key):
"""Check whether an entity has a Knowledge Graph ID."""
url = "https://kgsearch.googleapis.com/v1/entities:search"
params = {
"query": entity_name,
"key": api_key,
"limit": 1,
"languages": "en"
}
response = requests.get(url, params=params)
data = response.json()
if not data.get("itemListElement"):
return {"entity": entity_name, "kgmid": None, "type": None}
result = data["itemListElement"][0]["result"]
return {
"entity": entity_name,
"kgmid": result.get("@id", ""),
"type": result.get("@type", []),
"description": result.get("description", "")
}
# Example: check entities from your topic map
entities = ["structured data", "JSON-LD", "schema.org", "rich snippet"]
api_key = "YOUR_API_KEY"
for entity in entities:
result = lookup_kgmid(entity, api_key)
print(f"{result['entity']}: {result['kgmid'] or 'NO KGMID FOUND'}")
The distinction matters. An entity returned by the Knowledge Graph Search API has a kgmid – a canonical identifier in Google’s public Knowledge Graph, separate from string matching. “JSON-LD” with identifier kg:/g/11b6r2s4q3 is a specific thing Google understands as a data serialization format, not just a keyword pattern. Entities without kgmid values get string-matched against page content – a weaker signal, harder to rank for, because Google can’t confidently distinguish your usage from a different meaning of the same term.
When your target entity has no kgmid, Wikidata becomes the fallback identifier. Search for the entity on Wikidata, grab its Q-identifier, and use it as the @id in your JSON-LD structured data. Add the Wikipedia URL as a sameAs value. That gives Google an external disambiguation signal even without a Knowledge Graph record.
If you need to extract existing JSON-LD from pages at scale before starting this analysis, a Screaming Frog structured data audit covers the crawl setup.
Score Entity Salience with the Cloud Natural Language API
The Google NLP API for SEO guide covers setup, authentication, and basic entity extraction. This section focuses on comparative salience auditing – running an NLP content salience audit across your pages and your competitors’ pages to find where entity emphasis diverges.
Before sending any content to the Cloud Natural Language API, strip the boilerplate. Raw HTML includes navigation links, footer text, sidebar widgets, and cookie notices. Send that to the NLP API and you’ll get “Privacy Policy,” “Menu,” and “Login” competing for salience with your actual target entities. Garbage in.
from bs4 import BeautifulSoup
import trafilatura
def extract_body_text(html):
"""Extract main content text, stripping nav, header, footer, sidebar."""
soup = BeautifulSoup(html, "html.parser")
main = soup.find("article") or soup.find("main")
if main:
for tag in main.find_all(["nav", "aside", "footer", "header"]):
tag.decompose()
return main.get_text(separator=" ", strip=True)
return trafilatura.extract(html) or ""
Target <article> or <main> first. If the page lacks semantic HTML structure, Trafilatura handles the content extraction as a fallback. Run every URL through this function before any NLP call.
from google.cloud import language_v1
def get_entity_salience(text):
"""Return entities sorted by salience score."""
# Requires GOOGLE_APPLICATION_CREDENTIALS env var
# See the Google NLP API for SEO guide for auth setup
client = language_v1.LanguageServiceClient()
document = language_v1.Document(
content=text,
type_=language_v1.Document.Type.PLAIN_TEXT
)
response = client.analyze_entities(document=document)
entities = [
{
"name": entity.name,
"type": language_v1.Entity.Type(entity.type_).name,
"salience": round(entity.salience, 4),
"wiki_url": entity.metadata.get("wikipedia_url", "")
}
for entity in response.entities
]
return sorted(entities, key=lambda x: x["salience"], reverse=True)
The Cloud Natural Language API free tier covers 5,000 units per month. Note that Google defines a “unit” as 1,000 Unicode characters, not a single request. A batch audit of 80 pages (20 yours, 60 competitors) averaging 1,500 words each will consume approximately 700 to 900 units depending on character density – well within the limit. Unoptimized scripts that send raw HTML or frequent iterations during optimization cycles can erode this quota quickly. For initial exploration, use the Natural Language API demo for one-off manual checks before committing credits to automated batch processing.
No absolute salience threshold defines “good.” Salience scores are relative within a document – they approximately sum to 1.0 across all extracted entities. Your target entity should rank as the highest-salience entity, or at minimum land in the top two or three. If it doesn’t, the content is diluted.
Compare Your Salience Scores Against Competitors
Running the NLP API on your own pages tells you what Google extracts. Running it on the pages that outrank you tells you what Google prefers. The audit is a comparison.
Pull the top three ranking URLs for your target query. Apply the same boilerplate removal and entity extraction pipeline to each. Then build the comparison.
import csv
import requests
def batch_salience_comparison(urls, target_entities, output_file="salience_comparison.csv"):
"""Compare entity salience across multiple URLs."""
headers = {"User-Agent": "Mozilla/5.0 (compatible; SEOAuditBot/1.0)"}
results = []
for url in urls:
try:
html = requests.get(url, headers=headers, timeout=10).text
clean_text = extract_body_text(html)
entities = get_entity_salience(clean_text)
salience_map = {e["name"].lower(): e["salience"] for e in entities}
row = {"url": url}
for target in target_entities:
row[target] = salience_map.get(target.lower(), 0.0)
results.append(row)
except Exception as e:
print(f"Skipped {url}: {e}")
continue
with open(output_file, "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["url"] + target_entities)
writer.writeheader()
writer.writerows(results)
return results
# Usage
urls = [
"https://yoursite.com/target-page/",
"https://competitor1.com/ranking-page/",
"https://competitor2.com/ranking-page/",
"https://competitor3.com/ranking-page/"
]
target_entities = ["knowledge graph", "structured data", "entity", "schema.org"]
batch_salience_comparison(urls, target_entities)
This script uses requests.get, which returns raw HTML before JavaScript execution. It works for server-rendered pages. Client-side rendered sites (React, Next.js, Vue) need a headless browser like Playwright to capture the fully rendered DOM.
The output gives you a table like this:
| Entity | Your page | Competitor 1 | Competitor 2 | Competitor 3 |
|---|---|---|---|---|
| knowledge graph | 0.18 | 0.42 | 0.37 | 0.29 |
| structured data | 0.31 | 0.11 | 0.22 | 0.34 |
| entity | 0.08 | 0.19 | 0.15 | 0.12 |
| schema.org | 0.14 | 0.06 | 0.09 | 0.08 |
Read it column by column. A competitor scoring 0.42 salience for “knowledge graph” while you score 0.18 means their content makes that entity more central. They might mention it more frequently, make more specific claims about it, or surround it with stronger co-occurring entities. The gap column tells you where to rewrite.
Not every gap needs closing. If a competitor scores high on an entity outside your topic scope, ignore it. The comparison surfaces opportunities, not mandates. Focus on the entities in your topic map that competitors reinforce more strongly than you do.
The entity gap report – kgmid mappings, salience scores, competitor comparison – is your first audit deliverable. The next step examines whether the claims your content makes about those entities are structured clearly enough for machine extraction.
How Do You Validate Semantic Triples in Your Content?
Entities are the nouns. Semantic triples are the claims your content makes about them. A triple is a subject-predicate-object statement: “Google processes structured data.” Google is the subject. Processes is the predicate. Structured data is the object. Three components. One extractable claim.
Semantic triple validation checks whether your content actually makes these claims clearly – or buries them in vague language that NLP can’t parse into discrete relationships.
This isn’t an automated extraction pipeline. It’s a manual audit of your page’s strongest signals. Read your H1, each H2, and the first 100 words of each section. That scope gives you 3–5 core claims per page. Enough to diagnose systemic issues without dependency parsing or LLM extraction.
For each claim, ask: can I reduce this to a clean subject-predicate-object triple?
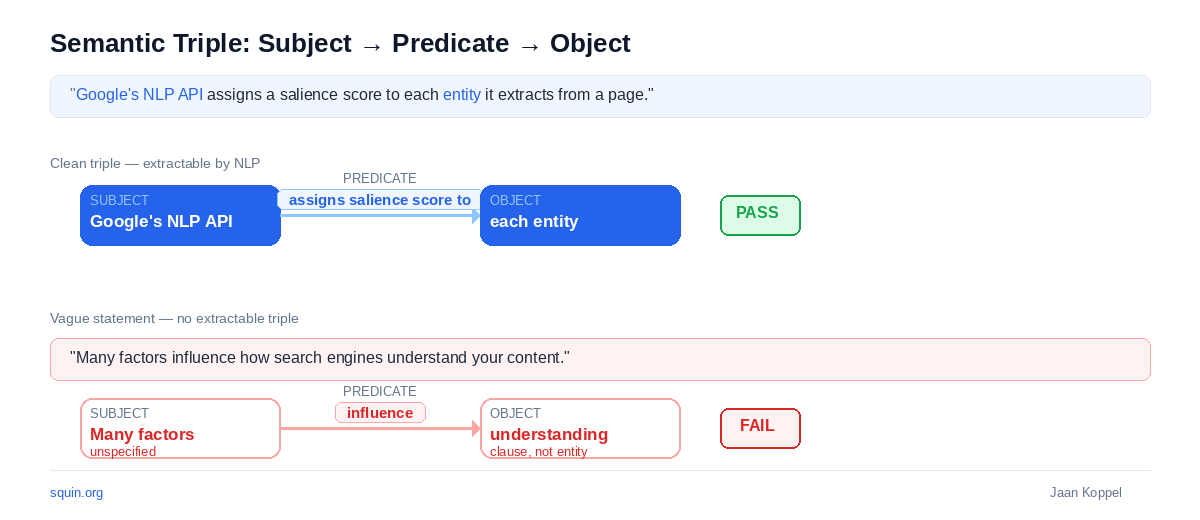
A failing statement: “Many factors influence how search engines understand your content.” What’s the subject? “Many factors” – unspecified. The predicate “influence” is vague. The object is a clause, not an entity. No triple. NLP extraction gets nothing actionable from this sentence.
The rewrite: “Google’s Natural Language API assigns a salience score to each entity it extracts from a page.” Subject: Google’s Natural Language API. Predicate: assigns salience score to. Object: each entity. Clean triple. Machine-readable even before you add schema.
Work through each audited claim the same way. Write the triple next to each statement in a spreadsheet – subject, predicate, object, pass or fail. Some sentences carry two triples. Some carry none.
import csv
def write_triple_sheet(triples, output_file="triple_validation.csv"):
"""Write triple validation results to CSV for tracking."""
with open(output_file, "w", newline="") as f:
writer = csv.DictWriter(
f, fieldnames=["source", "subject", "predicate", "object", "pass_fail"]
)
writer.writeheader()
writer.writerows(triples)
# Example: audit results from one page
triples = [
{"source": "H1", "subject": "Google's NLP API",
"predicate": "assigns salience score to", "object": "each entity",
"pass_fail": "pass"},
{"source": "H2-1", "subject": "Many factors",
"predicate": "influence", "object": "understanding",
"pass_fail": "fail"},
]
write_triple_sheet(triples)
The threshold is practical, not scientific. If more than half your audited claims fail the triple test, the problem isn’t missing keywords. The content needs rewriting for explicit claims. Every vague sentence is a missed signal – an entity relationship your competitors’ content states and yours doesn’t.
Triples tell you whether individual claims are machine-readable. The next question is whether your topic cluster makes enough of them across enough sub-topics to signal depth.
How Do You Measure Topical Coverage Density?
Coverage density is the measurement layer beneath topical authority. It tells you whether your cluster actually earns the authority signal or just looks like it should.
Most topical coverage audits count articles per sub-topic. That’s surface-level. Topical coverage density measures the ratio of entity mentions and relational claims across a cluster, relative to the total entity surface your topic map defines. Not article count. Entity depth per article.
Three variables define it:
entities_covered– unique entities from your topic entity map that appear in the cluster’s content, confirmed by NLP extraction from the entity gap analysis in §2. Keyword grep doesn’t count. An entity mention only registers if the NLP API returns it with a salience score above zero.entities_total– total entities in the topic entity map from your entity gap analysis. This is the baseline.claim_density_ratio– the average number of extractable entity-to-entity relational claims per page in your cluster, divided by the same metric averaged across the top 3 ranking competitors’ clusters. Above 1.0 means your content makes more explicit claims per page. Below 1.0 means competitors go deeper.
def topical_coverage_density(entities_covered, entities_total,
avg_claims_per_page, competitor_avg_claims):
"""Calculate topical coverage density for a content cluster.
This is a directional framework for tracking improvement
between audits, not an industry-standard metric. The absolute
score matters less than the delta over time.
Args:
entities_covered: Unique entities from the topic map found
in cluster content via NLP extraction.
entities_total: Total entities in the topic entity map.
avg_claims_per_page: Average extractable entity-to-entity
claims per page in your cluster.
competitor_avg_claims: Same metric averaged across top 3
ranking competitor clusters.
Returns:
Dictionary with entity coverage ratio, claim density ratio,
and combined density score.
"""
entity_coverage = entities_covered / entities_total if entities_total else 0
claim_density = (avg_claims_per_page / competitor_avg_claims
if competitor_avg_claims else 0)
combined = round((entity_coverage * 0.5) + (claim_density * 0.5), 3)
return {
"entity_coverage_ratio": round(entity_coverage, 3),
"claim_density_ratio": round(claim_density, 3),
"combined_density_score": combined
}
# Example: your cluster vs. competitors
result = topical_coverage_density(
entities_covered=18,
entities_total=25,
avg_claims_per_page=6.2,
competitor_avg_claims=4.8
)
print(result)
# {'entity_coverage_ratio': 0.72, 'claim_density_ratio': 1.292, 'combined_density_score': 1.006}
The weight split (0.5/0.5) is a starting point. Adjust it based on what moves rankings in your niche. The function exists so you can rerun it after every content update and track the delta.
The difference between thin and deep coverage: 50 articles that each mention “structured data” once produce a high article count but low claim density. Twenty articles that each make five explicit claims about how structured data works, what it connects to, and which tools validate it – that cluster signals more authority despite less volume because depth matters more than breadth.
Coverage density gives you a cluster-level score. The final step checks whether your structured data markup actually reflects what the content says.
How Do You Check Schema-Content Alignment?
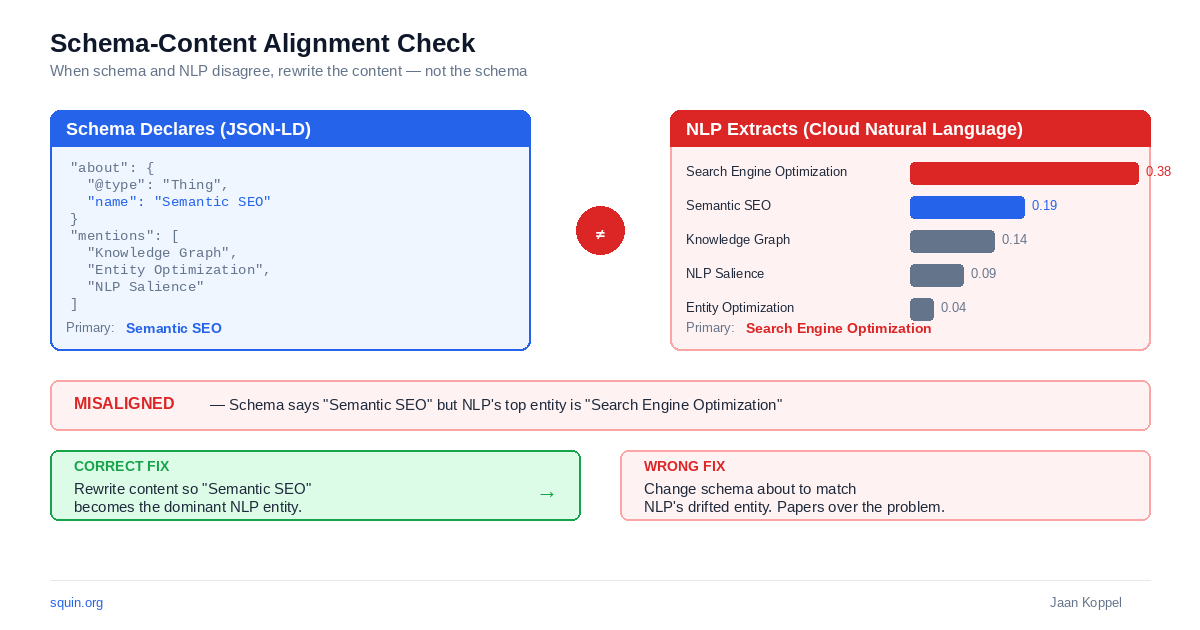
Schema markup is a label you apply. NLP extraction is what Google actually reads. When the two disagree, the content is the problem. Not the schema.
This distinction matters more than any other step in the audit. If you’re unfamiliar with @graph architecture and @id references, the JSON-LD tutorial covers the structural patterns you’ll need to read.
The audit is a direct comparison. Extract the primary entity from your page’s JSON-LD – the about or mainEntity property. Then run the same page through the NLP API using the extract_body_text function from §2.2. Does the schema’s declared entity match the NLP’s highest-salience entity?
First, extract the JSON-LD from your page’s HTML and isolate the Article node:
from bs4 import BeautifulSoup
import json
def extract_jsonld(html):
"""Parse JSON-LD blocks from HTML. Returns a list of dicts."""
soup = BeautifulSoup(html, "html.parser")
blocks = []
for script in soup.find_all("script", type="application/ld+json"):
try:
blocks.append(json.loads(script.string))
except (json.JSONDecodeError, TypeError):
continue
return blocks
def get_article_node(jsonld_blocks):
"""Extract the Article node from @graph or top-level JSON-LD."""
for block in jsonld_blocks:
if block.get("@type") == "Article":
return block
for node in block.get("@graph", []):
if node.get("@type") == "Article":
return node
return {}
Pass the Article node – not the raw JSON-LD block – to the alignment function. Most pages using @graph architecture nest the Article inside a @graph array, so the function needs the extracted node.
def check_schema_content_alignment(schema_json, nlp_entities):
"""Compare schema-declared entities against NLP-extracted entities.
Args:
schema_json: The Article node extracted from JSON-LD (use
get_article_node to extract from @graph structures).
nlp_entities: List of dicts with 'name' and 'salience' keys,
sorted by salience descending (output of get_entity_salience).
Returns:
Dict with alignment status, declared vs. extracted entities,
and any mentions gaps.
"""
# Extract declared entities from schema
about = schema_json.get("about", {})
declared_primary = about.get("name", "") if isinstance(about, dict) else ""
mentions = schema_json.get("mentions", [])
declared_mentions = [
m.get("name", "") for m in mentions if isinstance(m, dict)
]
# Top NLP entity
top_nlp = nlp_entities[0]["name"] if nlp_entities else ""
top_salience = nlp_entities[0]["salience"] if nlp_entities else 0
# Check primary alignment
primary_match = declared_primary.lower() == top_nlp.lower()
# Check mentions coverage
nlp_names = {e["name"].lower() for e in nlp_entities}
mentions_found = [m for m in declared_mentions if m.lower() in nlp_names]
mentions_missing = [m for m in declared_mentions if m.lower() not in nlp_names]
return {
"schema_primary": declared_primary,
"nlp_primary": top_nlp,
"nlp_primary_salience": top_salience,
"primary_aligned": primary_match,
"mentions_declared": len(declared_mentions),
"mentions_confirmed": len(mentions_found),
"mentions_missing": mentions_missing
}
When the result shows primary_aligned: False, don’t relabel your schema. If your Article declares about: "Entity A" but the NLP extracts Entity B at salience 0.6 and Entity A at 0.3, the content drifted. Rewrite the content so Entity A becomes dominant – more mentions, more specific claims, stronger co-occurrence with related entities. Changing the schema to say about: "Entity B" just papers over the drift.
One caveat: the highest-salience entity from NLP extraction is sometimes a generic term like “website,” “information,” or “content” rather than a meaningful topic entity. If your comparison returns primary_aligned: False but the NLP’s top entity is generic, filter by entity type – skip COMMON and check the first entity typed as ORGANIZATION, CONSUMER_GOOD, WORK_OF_ART, or OTHER depending on your content category.
The mentions check catches a subtler problem. Your schema might declare four mentions entities, but NLP only extracts two of them. The other two aren’t reinforced by the content. They’re empty labels. Either add substantive claims about those entities or remove them from the markup. Google’s structured data guidelines expect markup to reflect page content – not aspirational content you haven’t written yet.
A full semantic SEO case study (coming soon) will walk through this alignment process on a live page with before-and-after NLP scores.
What Are the Most Common Semantic Audit Mistakes?
Auditing keywords instead of entities. Checking whether “semantic SEO” appears 15 times on a page is keyword density analysis. A semantic audit checks whether Google’s NLP identifies “semantic SEO” as a disambiguated entity with high salience. Occurrence count and entity recognition are different signals.
Treating schema validation as schema auditing. The Rich Results Test checks syntax – valid JSON-LD, recognized types, required properties present. It doesn’t check whether your schema’s declared about entity matches the entity the NLP actually extracts from your content. A page can pass validation with zero semantic alignment.
Measuring topical coverage by article count. Fifty thin articles that each mention “structured data” once don’t signal topical authority. Twenty articles making five explicit relational claims each produce higher coverage density. Volume without depth is noise.
Ignoring the competitor comparison. Running the NLP API on your pages alone gives you absolute salience scores with no context. A 0.4 salience for your target entity means nothing until you know the page ranking above you scores 0.8. The batch comparison from §2.3 is where the gaps become visible.
Skipping boilerplate removal. Send raw HTML to the NLP API and you’re auditing your navigation menu, sidebar links, and footer text alongside your article content. Every audit call needs the extract_body_text step first. No exceptions.
Running the audit once. Entity landscapes shift. Google updates its NLP models. Competitor content changes. Quarterly audits on core pages catch drift before it compounds. Track your coverage density score and salience deltas between runs – the trend matters more than any single snapshot.
Frequently Asked Questions
What is a semantic SEO audit?
A semantic SEO audit evaluates how well search engines understand your content at the entity level. It measures entity coverage gaps, NLP salience alignment, semantic triple clarity, topical coverage density, and schema-content consistency – going beyond traditional technical audits that focus on crawlability and keyword placement.
How do you perform an entity-based SEO audit?
Start by mapping your target entities using the Knowledge Graph Search API and Wikidata. Run your content and competitor content through Google’s Cloud Natural Language API to compare entity salience scores. Validate that your content makes explicit semantic triples. Check that your schema markup aligns with what the NLP actually extracts. The entity map guide covers the baseline mapping step.
What tools do you need for a semantic SEO audit?
The core tools are Google’s Knowledge Graph Search API (for kgmid verification), Google’s Cloud Natural Language API (for entity extraction and salience scoring), and a schema validator like Google’s Rich Results Test (for structured data syntax). Python handles batch processing and comparison workflows. No paid SEO tool fully replicates this stack.
Does schema markup affect semantic SEO audit results?
Schema markup reinforces entity signals, but only when it matches what the NLP extracts from your content. Misaligned schema – where the declared about entity differs from the NLP’s highest-salience entity – weakens the signal. The fix is rewriting content to match the schema’s intent, not changing schema labels to match drifted content.
Where This Fits
The semantic SEO guide covers the full framework these audit steps measure against. A semantic SEO case study (coming soon) walks through this audit applied to a live site.