
Google doesn’t process your content the way it did five years ago. The pipeline changed. What you optimize, how you structure it, and how you validate it changed with it.
That shift isn’t a branding difference between “traditional” and “semantic” SEO. It’s a mechanical one. Google’s infrastructure now handles queries, documents, and result matching through three layers that work differently from the lexical system most SEO workflows were built for.
This article breaks down where those models diverge, what changes in your day-to-day workflow, and which traditional signals still carry weight inside the semantic system. If you need the foundational context first, start with our complete semantic SEO guide.
Where the Models Diverge – Three Processing Layers
The difference between lexical and semantic search isn’t a spectrum. It’s three distinct layers where Google processes your content through fundamentally different mechanisms.
| Processing Layer | Lexical Model | Semantic Model |
|---|---|---|
| Query interpretation | Decomposes query into tokens, expands with synonyms | Resolves query to intent + entities |
| Ambiguity handling | Query expansion – adds related terms to broaden matching | Intent disambiguation – identifies which meaning the user intended |
| Document understanding | Scores keyword presence, frequency, and placement | Extracts entities, maps relationships, scores salience |
| Scoring model | TF-IDF / BM25 (probabilistic term-frequency scoring) | Named-entity recognition + entity resolution against the Knowledge Graph |
| Result matching | Sparse retrieval – keyword overlap between query and document | Dense retrieval – vector similarity in embedding space |
| Zero-overlap matching | Effectively impossible. No shared terms or close variants, no match. | Standard. Shared meaning is enough. |
Layer 1: How Google Interprets Your Query
The lexical model treated a query as a bag of words. “Best budget laptop for video editing” was a set of tokens. Google matched pages containing those tokens, weighted by frequency and placement. When the query was ambiguous – “apple” could mean a fruit or a company – the system handled it through query expansion: adding related terms like “iPhone” or “recipe” to broaden the match set and let ranking signals sort the results.
Google resolves the query to an intent and a set of entities. “Best budget laptop for video editing” becomes a commercial-investigation intent targeting three intersecting concepts: laptop as a product type, budget as a price constraint, and video editing as a use case. Google’s own How Search Works documentation describes this as understanding “the intent of your query” – not just what words you typed.
Google calls this shift “strings to things.” It’s not a slogan. It’s the mechanical description of what changed. A text string has no identity. The entity Apple Inc. has a type (Organization), attributes (CEO, headquarters, stock ticker), and relationships to other entities in the Knowledge Graph. When Google resolves the string “Apple” on your page to that entity, it stops matching words and starts matching meaning.
Hummingbird (2013) shifted query processing from lexical decomposition to semantic interpretation at scale. RankBrain (2015) handles the edge cases – novel queries Google hasn’t seen before, where it maps unfamiliar phrasing to entities and intents it already understands.
Ambiguity no longer gets handled by expanding the query with more terms. It gets handled through intent disambiguation – identifying which meaning the user intended based on context signals in the query itself.
Layer 2: How Google Reads Your Document
Under the lexical model, Google scored your page by keyword presence and placement. Target keyword in the title tag, the H1, the first paragraph, the H2s, and distributed through the body. The scoring math was TF-IDF and BM25 – probabilistic models that weight term frequency, document length, and corpus-level rarity to determine relevance. The more precisely you placed your target keyword, the stronger the signal.
Under the semantic model, Google runs your content through NLP models – BERT and its successors – that extract a different kind of signal entirely. Named-entity recognition identifies the entities in your text: people, organizations, concepts, places. Entity resolution then maps those extracted entities to nodes in the Knowledge Graph, connecting the words on your page to known entries in Google’s structured database.
The distinction matters at the page level. Keyword frequency tells Google which strings appear on your page. Entity extraction tells Google which things your page is about. A page that mentions “Knowledge Graph” fourteen times and a page that defines the Knowledge Graph’s structure, explains its data sources, and places it in relationship to Wikidata and entity disambiguation – those produce very different NLP outputs. The second page has higher entity salience. Not because it used a keyword more, but because it covered the entity with precision.
This is also where entity SEO connects. Your content’s entity signals are what Google uses to decide what your page covers at the conceptual level. Keyword placement still exists as a signal. It’s now one input among several, not the primary one.
One persistent myth needs correcting. “LSI keywords” still appears in SEO advice as if it’s a modern semantic signal. It isn’t. Latent Semantic Indexing is a sparse-matrix decomposition technique from 1988, designed for small document collections. Google’s John Mueller has explicitly stated there is no concept of LSI keywords in Google’s systems [VERIFY exact source]. What Google uses – BERT, MUM, and their successors – are dense vector models that compute meaning through learned representations, not term co-occurrence matrices. These are architecturally different systems. Drop “LSI keywords” from your vocabulary.
The contrast between lexical vs semantic search is sharpest at this layer. One counts strings. The other extracts meaning.
Layer 3: How Google Matches Results to Queries
The lexical model used sparse retrieval. Google computed relevance by measuring keyword overlap between the query and the document, then weighted the result with signals like PageRank. If neither the query terms nor close lexical variants appeared on the page, the page effectively didn’t match.
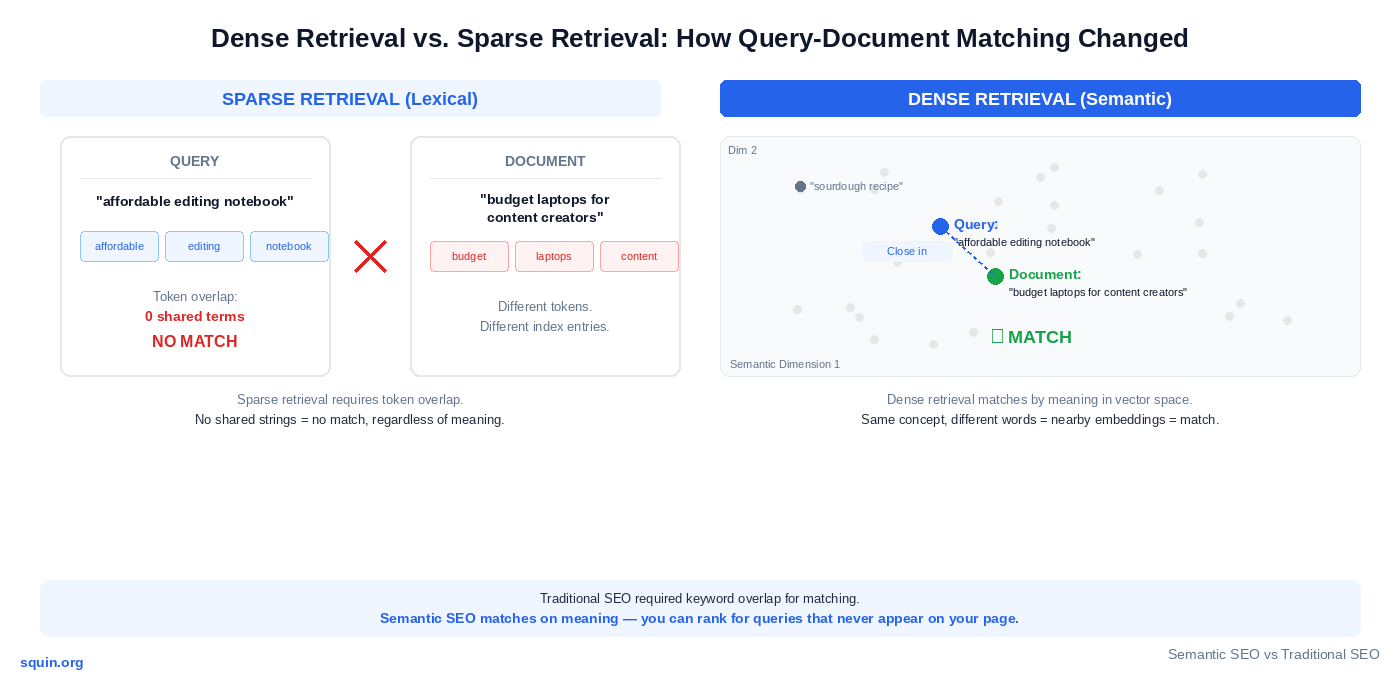
The semantic model adds dense retrieval. Google converts queries and passages into vector embeddings – dense numerical representations in high-dimensional space. Queries and passages that share meaning end up close together in that space, even if they share zero keywords. Google doesn’t use dense retrieval alone – sparse retrieval still generates initial candidates. Dense models re-rank and match at the passage level. The practical shift is that content can now match queries it wouldn’t have matched under sparse retrieval alone.
Vector embeddings in SEO operate at this retrieval level. The query “affordable editing notebook” and a page about “budget laptops for content creators” have minimal lexical overlap. Under sparse retrieval, that page barely matches. Under dense retrieval, both map to nearby points in embedding space because the underlying concepts overlap. Google matches them based on semantic similarity, not shared strings.
The practical consequence: you can rank for queries that never appear on your page. Not through tricks. Through meaning. If your content covers the entity and its relationships with enough depth, the embedding captures that – and Google can match it to queries phrased in ways you never anticipated.
Traditional SEO was built on a system where keyword presence was a hard prerequisite for matching. That prerequisite no longer holds. Your content strategy needs to account for a matching system that operates on meaning, not strings.
The three layers – intent resolution, entity extraction, and vector matching – are the pipeline. Everything that changes in your workflow follows from them.
What Changes in Your SEO Workflow
The three processing layers aren’t abstract. Each one changes a specific step in how you research, plan, write, mark up, and validate content. Five steps, five shifts.
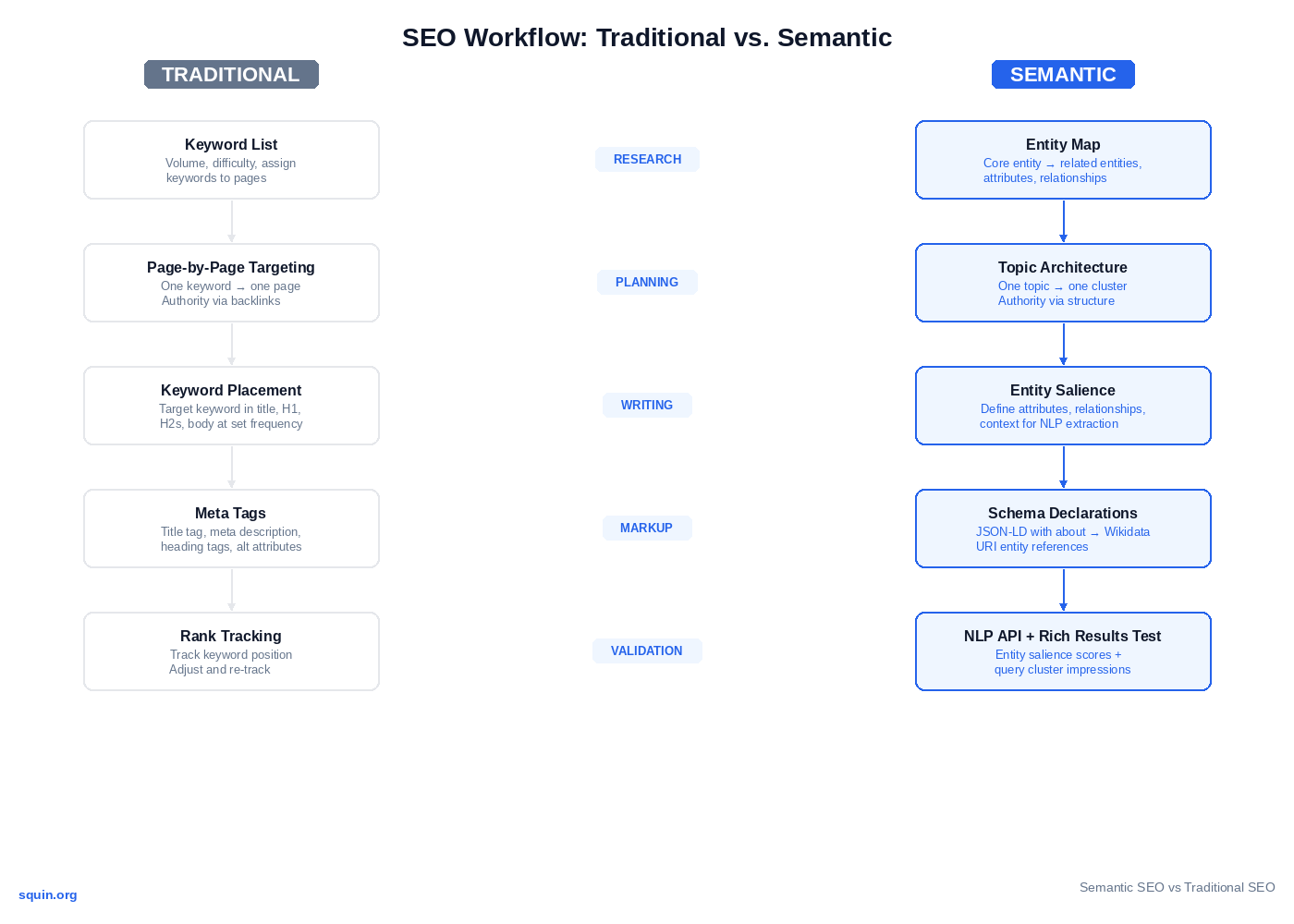
Research – Entity Maps vs. Keyword Lists
The traditional research workflow starts in Ahrefs or Semrush. You pull keyword volume, filter by difficulty, build a list, assign each keyword to a page. The output is a spreadsheet of strings ranked by search volume.
The semantic workflow starts with a different question: which entities does your site need to own? You identify the core entity for your topic, then map outward – related entities, their attributes, the relationships between them. Keywords still appear in this process. They become a byproduct of the entity map, not the starting input.
Knowledge graph optimization is the goal of this research phase. You’re targeting which entities Google should associate with your domain, not which strings you want to appear for. The entity map tells you what content to create. The keyword list used to do that job. It can’t anymore – not when Google matches queries to entities, not tokens.
The research methodology is its own discipline. Our guide on how to find and use semantic keywords walks through the full process from entity identification to keyword extraction.
Content Planning – Topic Architecture vs. Page-by-Page Targeting
Traditional content planning assigns one keyword to one page. The editorial calendar is a list of keywords with publish dates attached. Each page stands alone. Authority accumulates through backlinks, not structure.
Semantic content planning works at the topic level. One subject maps to one cluster – a pillar page covering the full scope, with cluster articles handling each sub-entity in depth. Internal links between them signal to Google that these pages are structurally related, not isolated.
The contrast is topical authority vs keyword density. Keyword density is a per-page metric. You optimize one page, and that optimization stays on that page. Topical authority compounds across pages. Each new cluster article strengthens every other page in the cluster, because Google evaluates your site’s coverage of the topic as a whole – not one keyword at a time.
squin.org is built on that model – three pillar pages, each with cluster articles nested underneath. Every cluster article connects back to its pillar. Every pillar links out to its clusters. The structure is the signal. Our guide to building topical authority covers the architecture and measurement in detail.
Writing – Entity Salience vs. Keyword Placement
Traditional SEO writing follows a placement checklist. Target keyword in the title tag. In the H1. In the first 100 words. In at least two H2s. Distributed through the body at a “natural” frequency. The signal is keyword presence in specific positions.
Semantic writing targets entity salience – how prominently and clearly you discuss an entity, as measured by Google’s NLP models. Repeating an entity name doesn’t increase salience. Writing about the entity with precision does.
Two passages covering the same entity produce very different NLP outputs:
“Structured data is good for SEO. You should add structured data. Structured data helps your rankings.”
“Structured data is machine-readable code embedded in your HTML that declares entities and their properties using the Schema.org vocabulary. Google’s parser extracts these declarations and maps them to Knowledge Graph entries, giving the search engine explicit entity signals rather than inferred ones.”
The first passage mentions the entity three times. The second defines its attributes and relationships. Run both through Google’s Cloud Natural Language API – a REST endpoint with a free tier of 5,000 requests per month – and the difference is measurable. The first passage returns a salience score around 0.04 for “structured data.” The second returns roughly 0.33, because it provides the context NLP models need to extract meaning rather than just count mentions. Salience runs from 0 to 1 across all entities on a page, and scores sum to approximately 1.0. What matters is rank order – your target entity should hold the highest score relative to every other entity on the page.
The takeaway: write about the entity, not just with the entity name.
Markup – Schema Declarations vs. Meta Tags
Traditional on-page markup communicates through textual hints. The title tag tells Google the page topic. The meta description summarizes content. Heading tags signal structure. Alt attributes describe images. All useful. All require Google to infer meaning from text.
Schema markup in JSON-LD makes entity declarations explicit. Your about property points directly to a Wikidata URI, telling Google exactly which entity your page covers – no inference required.
The contrast in code:
Traditional (textual hint):
<title>Knowledge Graph: How Google Connects Entities</title> <meta name="description" content="A guide to Google's Knowledge Graph and how it stores entity relationships.">
Semantic (explicit entity declaration):
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Knowledge Graph: How Google Connects Entities",
"about": {
"@type": "Thing",
"@id": "http://www.wikidata.org/entity/Q648625",
"name": "Knowledge Graph",
"sameAs": "https://en.wikipedia.org/wiki/Knowledge_Graph_(Google)"
}
}
The title tag says “Knowledge Graph” as a string. The JSON-LD declares the Knowledge Graph as a specific entity with a Wikidata identity that Google can resolve against its own graph. Same topic. Different signal depth.
This example shows only the about declaration. A production Article block includes @id, author, datePublished, and other properties – our JSON-LD tutorial covers the complete pattern, including nesting and multi-entity graphs.
Validation – NLP API + Rich Results Test vs. Rank Tracking
Traditional validation has one feedback loop. Publish. Check rankings. Adjust on-page signals or build links. Check rankings again. The metric is position for a specific keyword.
Semantic validation adds two layers. First, run your content through the Google Cloud Natural Language API before publishing. It returns the entities Google extracts from your text, their types, and their salience scores. If your target entity doesn’t hold the highest salience on the page, revise before you publish – not after.
Second, validate your schema through Google’s Rich Results Test. It parses your JSON-LD, flags errors, and confirms which rich result types your markup qualifies for.
One step most practitioners skip: before optimizing for an entity, confirm it exists in Google’s Knowledge Graph. The Knowledge Graph Search API lets you query by entity name and check whether Google has a node for it. If there’s no entry, your entity target may need to shift – or you need to build the entity’s presence through Wikidata and authoritative references first. Our [Knowledge Graph Search API guide] (coming soon) walks through the full workflow.
Rank tracking isn’t obsolete. It becomes one signal among several. The semantic measurement is query cluster impressions in Google Search Console – whether your visibility expands across related queries you never explicitly targeted. Filter GSC’s Performance report by queries related to your topic and track total impressions over time. That expansion is the sign that topical authority is compounding.
The workflow shifts are concrete. But they raise an obvious question: if semantic SEO changes this much, what happens to the traditional signals you’ve spent years building?
What Traditional SEO Signals Still Carry Weight
Semantic SEO doesn’t replace technical fundamentals. It builds on top of them. The signals below still matter – but their function inside the semantic model is different from what most practitioners assume.
Crawlability and indexing. None of the semantic processing described above happens if Google can’t crawl and render your page. robots.txt configuration, site architecture, page speed, Core Web Vitals – these are prerequisites, not strategy. Google’s How Search Works documentation describes crawling and indexing as the first two stages of its pipeline. Entity extraction, Knowledge Graph resolution, and vector matching all happen after indexing. Break the prerequisites and nothing downstream works.
Title tags and heading structure. Google still uses these as strong relevance signals. What changed is how they’re parsed. A title tag isn’t just checked for keyword presence anymore – it’s parsed for entity mentions. “Knowledge Graph: How Google Connects Entities” gives Google an entity to resolve. “Best Knowledge Graph Guide 2026 | Top Knowledge Graph Tips” gives Google a string repeated three times. The first is more useful to a system that extracts meaning. The second was built for a system that counted terms.
Backlinks. Still a ranking signal. But the mechanism is shifting. A backlink from a page about structured data to your schema markup guide reinforces entity co-occurrence – Google sees both pages discussing the same entities and strengthens the association between your domain and that topic. A backlink from an unrelated coupon aggregator passes PageRank but contributes nothing to entity recognition. Traditional link building measured authority transfer. Semantic link building measures whether the linking context reinforces your entity associations.
URL structure. Clean, hierarchical URLs help Google parse site structure. Pillar/cluster nesting like /semantic-seo/topical-authority-seo/ signals a topic relationship at the URL level. Not a ranking factor on its own. A structural signal that complements your internal linking and schema.
The pattern across all four: these signals don’t compete with semantic optimization. They’re the infrastructure it runs on. Optimizing only for crawlability, title tags, backlinks, and URL structure – without entity coverage, schema declarations, or topical depth – is optimizing for a system that no longer operates in isolation. The foundation stays. The strategy built on it has changed.
That change accelerates in one specific direction – and it’s the direction most practitioners haven’t accounted for yet.
Why Does the Gap Widen in AI Search?
AI Overviews changed the stakes of this comparison. The difference between traditional and semantic optimization is no longer just about rankings. It’s about whether your content gets cited or gets summarized over.
Google’s AI Overviews use retrieval-augmented generation. The system retrieves content from pages Google has already parsed into entities and relationships, then synthesizes an answer. The selection mechanism pulls from sources where Google can confidently identify what entities the page covers, how those entities relate, and how authoritatively the page treats them.
Content optimized only for keywords can still appear in the retrieval set. But it’s harder for the generative model to extract structured facts from prose that was written for keyword placement rather than entity clarity. A page with explicit entity declarations – schema about properties pointing to Wikidata URIs, named entities defined with attributes and relationships – gives the model machine-readable facts to ground its response. A page with the target keyword in the title, H1, and body fourteen times gives it text to summarize.
The difference is attribution vs. invisibility. Cited sources get a link in the AI Overview. Summarized-over content influences the answer with zero traffic back to your site.
This extends beyond Google. Bing’s Copilot, Perplexity, and other answer engines all retrieve and process web content. They all perform better with pages that declare entities in machine-readable formats. Schema.org is the shared vocabulary across every one of them. JSON-LD with explicit entity references isn’t a Google-specific optimization. It’s the format these systems are built to consume.
Traditional optimization doesn’t prepare your content for this. Keyword placement, meta descriptions, and backlink profiles don’t produce the structured entity signals that generative systems select for. Semantic optimization does – not as a bonus, but as the baseline for visibility in a search environment where the answer appears above the results.
The gap between these two approaches isn’t static. It widens every time Google expands AI Overview coverage, every time a new answer engine launches.
What Are the Common Mistakes When Shifting to Semantic SEO?
Six errors show up repeatedly. Every one comes from carrying a traditional habit into a semantic workflow without adjusting the logic behind it.
Treating entity names like keywords. The traditional instinct is to increase frequency. More mentions, stronger signal. That logic doesn’t transfer. Repeating “Knowledge Graph” 47 times across a page doesn’t increase entity salience. Writing about the Knowledge Graph’s structure – its data sources, how it stores relationships, how Google uses it for disambiguation – does. Entity salience comes from context and precision, not repetition. The old instinct actively undermines the new signal.
Adding schema without content depth. This is the most common shortcut when practitioners hear “structured data matters.” They add Article schema with an about property pointing to a Wikidata URI, but the page itself is 400 words of surface-level content. Schema confirms entities your content already covers. It doesn’t create entity signals from nothing. If Google’s NLP extracts thin coverage from your text, a JSON-LD block declaring deep coverage creates a mismatch – not a reinforcement.
Building topic clusters with no internal linking architecture. Publishing twelve articles on related subtopics doesn’t build topical authority if the pages don’t link to each other. The linking is the signal. It tells Google that these pages share entity relationships and form a coherent topic structure. Without it, Google sees twelve isolated pages. Not a cluster.
Measuring semantic SEO with traditional metrics only. Single-keyword rank tracking measures one position for one string. It can’t tell you whether your visibility is expanding across a query cluster – which is the whole point of topical authority. The semantic measurements: query cluster impressions in GSC, rich result appearances across your schema types, and Knowledge Panel triggers for your brand or author entities.
Ignoring entity disambiguation. Writing about “Mercury” without co-occurring entities that signal which Mercury you mean – planet, element, Roman god, car brand – forces Google to guess. Every ambiguous entity on your page is a point where semantic processing can misfire. This isn’t a concept that appears in traditional SEO workflows.
Assuming semantic SEO replaces everything. The mirror-image mistake. Dropping technical fundamentals because “entities are all that matter now” leaves your semantic optimization sitting on a broken foundation. Crawlability, page speed, clean architecture – those are preconditions. They were before. They still are.
Frequently Asked Questions
What is the difference between traditional SEO and semantic SEO?
Traditional SEO optimizes pages for specific keyword strings – placing them in titles, headings, and body text, then building backlinks to increase authority for those terms. Semantic SEO optimizes for topics, entities, and their relationships – structuring content so Google’s NLP models can extract entities, resolve them against the Knowledge Graph, and understand what your site covers at the conceptual level. The core shift: traditional SEO asks “what keyword do I target?” Semantic SEO asks “what entity does Google need to associate with my site?”
Does semantic SEO replace traditional SEO?
No. Semantic SEO builds on technical fundamentals that traditional SEO established – crawlability, page speed, clean URL structure, and heading hierarchy still matter. What changes is the optimization layer above those fundamentals. Instead of keyword frequency and backlink volume as primary signals, entity salience, topical coverage, and schema declarations become the active optimization targets. The foundation stays. The strategy on top of it evolves.
What is a practical example of semantic SEO?
A traditional approach to ranking for “schema markup” would target that keyword in the title, place it in headings, and build backlinks. A semantic approach creates a pillar page covering the full topic, writes cluster articles on JSON-LD, FAQPage schema, and validation tools, interlinks everything, adds Article schema with about pointing to the Schema.org Wikidata entity, and validates that the primary entity holds the highest salience score via the NLP API. The keyword appears – but it’s a byproduct of entity coverage, not the goal.
How do you measure semantic SEO results?
Track three things beyond keyword rankings. Query cluster impressions in Google Search Console – gaining impressions for queries you never explicitly targeted means topical authority is compounding. Rich result appearances – schema generating visible SERP features means Google is reading your entity declarations. Entity salience via the NLP API – run your pages periodically and confirm your primary entity holds the top salience score.